社内WikiのAI検索システムを作ってみた
目次
- はじめに
- 生成AI活用の経緯・生成AIサービスの一例の紹介
- 社内WikiのAI検索システム構築
- システム構成
- Dify
- Ollama
- Qwen3:14B
- モデルと量子化選定
- Difyのワークフロー
- 全体像
- 実行結果
- 最後に
はじめに
プログラマーの石戸です。
近年、社内Wikiを活用した情報共有は多くの企業で当たり前になりました。しかし、情報量が増えるほど「本当に必要な情報にすぐ辿り着けない」という課題も浮き彫りになっています。
弊社でも業務マニュアルや議事録、Unreal Engine関連の技術メモなど、日々多様な情報がWikiに蓄積されています。
そんな中、「AIで社内Wikiの情報検索をもっと効率化できないか?」という思いから、AI検索システムを試しに作ってみました。趣味で試したものですが、実用的な部分もあるかと思い今回記事にしてみました。
本記事では、その過程で得られた知見や工夫のポイントをまとめてご紹介します。
生成AI活用の経緯・生成AIサービスの一例の紹介
AI検索システムの話に移る前に、まずは生成AIを活用することになった経緯と、生成AIを活用したサービスの一例を紹介します。
llamafile
数年前にChatGPTが話題になってしばらくしてから「llamafile」というツールを知りました。
llamafileはAIモデルを内蔵した1ファイル構成の.exe形式で、ダブルクリックするだけでサーバーが起動して自動でブラウザが開き、すぐにLLMを用いたチャットができるという、非常にお手軽なものです。
それを使ったとき「今実行しているこのPCでAIが動くんだ!」と大きな衝撃を受けました。
ローカルLLM
それからというもの、ローカルLLMの虜となり、プライベートの半分はAIを試し、その性能の進化に驚かされるという日々を送っています。
特に実感しているのは、その進化のスピードです。新しいものを試すだけでも、次々と進化していく様子には圧倒されます。こうした趣味としての取り組みの中から、「これは実用的に使えるかもしれない」と思えるものが生まれてきたため、今回記事としてまとめることにしました。
なお、動作させているPCはRTX4070(VRAM 12GB)搭載の一般的なゲーミングPC1台のみです。AI専用の高性能マシンではなく、あくまで一般的な環境で構築した事例として読んでいただければ幸いです。
社内WikiのAI検索システム構築
といったことで今回構築したのは、社内Wikiの記事を対象にAIで検索するシステムです。
実は以前、Gemma2やRAGが話題になったころに検索システムを作成したのですが、細分化された記事に思うようにヒットさせることが出来ず、満足のいくAI検索にはなりませんでした。
今回はQwen3を試してみて、以前より格段に精度の高い回答が得られ、前回のものより的確な回答が得られるものが構築できました。
ここまでの品質があれば、実用に向けていろんな改良や、取り組み、応用ができると感じました。
システム構成
- OS:Windows11
- CPU:Core i7-14700F
- メモリ:32GB
- GPU:RTX 4070(VRAM 12GB)
- サービス構成:Dify + Ollama + Qwen3:14B
- 検索対象:Wordpress(キーワード検索の結果、数百件のヒット)
今回は個々のプロジェクトのWikiではなく、社内全体の情報が載っているページにて検索を行いました。
規模が大きいものではないため、情報が多いともっと複雑なシステムを組む必要がありそうだと感じました。
Dify
ノードベースでAIのワークフローを構築できるWebサーバーです。
AIの呼び出し、HTTPリクエスト、Pythonによるデータ加工などを簡単に実装できます。
Ollamaを含む複数のAIエンジンに対応しています。
Ollama
PC上で効率的にAIを動かすためのエンジンです。
量子化モデルを使うことで、VRAM 12GBのRTX 4070でも大規模モデルが実行可能です。
実行はCUDAベースですが、VRAM不足時は自動でCPUにフォールバックします。
ただし、推論速度が著しく低下するため、基本的にはVRAMに収まるように構成すべきです。
KVキャッシュの量子化の有効化
※KVキャッシュの量子化についての詳細は後述します。
Ollamaは引数でフラッシュアテンションとKVキャッシュを有効化することはできません。また、裏で使われているllama.cppはKVキャッシュの量子化を使う場合、フラッシュアテンションを有効化しなければ使えません。理由は探しきれませんでしたが、実装コストや精度面からそうなってるのかなと思いました。
KVキャッシュの量子化を使う場合は、以下二つの環境変数をセットしてからOllamaを再起動してください。
OLLAMA_FLASH_ATTENTION=1
OLLAMA_KV_CACHE_TYPE=q8_0
※f16(デフォルト)、q8_0、q4_0が使えます。
今回VRAMは潤沢にありません。精度を確認しq8_0の使用に決めました。
フラッシュアテンションとメモリ使用量
コンテキストサイズが大きいと、フラッシュアテンションを有効にしただけでもメモリ使用量が大幅に抑えられます。
省メモリ運用にあたって、
- モデルの量子化
- フラッシュアテンションの有無
- KVキャッシュの量子化
の設定が大事です
Qwen3:14B
2025年5月1日にAlibabaがリリースしたオープンソースの大規模言語モデルです。
今回使用したのは「Qwen3:14B」(モデル量子化:Q4_K_M、コンテキストサイズ:30k、KVキャッシュ量子化:Q8_0)です。
RTX4070(12GB)で秒間約40トークンの出力が出来ましたので申し分ないパフォーマンスでした。
モデル選定の詳細は以下のとおりです。
モデルと量子化選定
一般的なグラボで動作させるためには省メモリ化がカギとなります。
ollamaに使われているllama.cppソリューションにおいて、省メモリ化には下記二つの重要な項目があります。
- モデルウェイトの量子化
- KVキャッシュの量子化
この二つはそれぞれ別の設定で、量子化によって劣化の仕方も変わってきます。
モデルウェイトの量子化
主に知識の精度や語彙に影響します。
例えば「青い空」が「空」と省略されてしまうなど、詳細を失います。失いすぎると間違った答えに進んでしまうため、その中で「Q4_K_M」が一番バランスが良いとされています。
最近のollamaでダウンロードされるモデルのデフォルトはこのQ4_K_Mになっています。実際試してみても、Q8にしたからと言って明らかな変化がわかるほどではありませんでした。また、3bitまで行くと、精度の劣化が目に見えてわかったので、今回は標準のQ4_K_Mを採用しました。
※ただし2Bなどの小さいモデルでは量子化が品質にかなり影響してきます。そういうモデルではQ8_0までが良いとされています。
KVキャッシュの量子化
KVキャッシュは推論時のコンテキストの関係情報を保持するものです。
KVキャッシュは簡単に言ってしまうと、コンテキストの1文字がほかのすべての文字に対してどう影響するのか、という情報保持するものです。アテンションの計算結果を保持して次回に使いまわす高速化に用いるためキャッシュという名前がついているようです。(※KVキャッシュの認識が間違っていたら申し訳ございません。)
コンテキストサイズが大きいとKVキャッシュは数GBと膨れ上がります。デフォルトではf16ですが、量子化のQ8_0形式と、Q4_0形式が選べます。10k以上コンテキストの場合、Q4_0ですと精度劣化が顕著になるようです。
実際に試したところ、Q8_0に比べると、入力コンテキストを取りこぼしたり、命令を守れなかったりしました。Q4_0にすることで、128kコンテキストが視野に入りますが、今回は精度を取りたかったのでQ4_0や128kコンテキストは見送りました。
そのため、今回は12GBメモリのおさまりが良よかったQwen3:14B(Q4_K_M) 30kコンテキスト(Q8_0)を使用しています。
他の候補の選定
Gemma3 12B
Gemma2が登場したときは、プロンプトの指示をかなり守ってくれたため、ずっと使っていました。
Gemma3はさらに大きく進化していて指示は守ってくれるのですが、Qwen3に比べ創作が目立ち、今回は採用しませんでした。推論速度が速い分そういうところが苦手なのかな?と思いました。
言葉の選び方や実行速度はGemma3が良かったのですが、今回はとにかく正確性を重視します。その点Qwen3はかなり正確で、コンテキストの内容に無いものは答えなかったりと、指示を守ってくれました。
この辺はどちらが良いというよりかは、適材適所なんだろうと思いました。
Qwen3:8B(Q4_K_M)、80kコンテキスト(Q8_0)
Qwen3は128kコンテキストまで対応していますが、12GBのVRAMに収まるのはq8_0に量子化したKVキャッシュで、80kコンテキストまでです。
30kからすると2.5倍の記事を投入できることになりますが、80kコンテキストだと、内容を取りこぼしたり、パフォーマンスが半分以下になったりで、採用を見送りました。試しに量子化無しのKVキャッシュを試してみましたが、出力精度の差はあまりかわりませんでした。
Qwen3はネイティブ32kをRoPEによって128kにまで拡張できる仕組みがあるようなのですが、その拡張の際に取りこぼすのではないかと思いました。
また、基本的な要約などの精度は8Bでも全く問題がありませんが、少し複雑な出力形式を厳格に守ってほしい場合などで、若干の揺らぎが発生しました。これはQ4_K_Mのせいなどもあるでしょうか、いずれにせよメモリのおさまりのい14Bを採用しました。
Qwen3-30B-A3B
性能は本当にすごく、ローカルでここまでのものが動くなんて、、と進化に感動しっぱなしです。このモデルでも秒間18トークン出力できました。
UE5のWedgetの作り方を聞いたらしっかり答えてくれました。ぱっと見はChatGPTと変わりが無いように見え、これがRTX4070で・・と言葉が出ません。
ただし、Qwen3:14Bに比べると実用的な速度ではなかったため採用は見送りました。秒間18トークンでも早いですが、40トークンに比べると実利用として少しじれったかったです。もうちょっと上位のVRAMがあればすべてGPUで推論出来るでしょうし、ローカルLLMの時代が来そうです。
Difyのワークフロー
前置きが長くなってしまいましたが、組んだDifyノード自体は大したものではありません。
以下のような流れで組みました。
- 検索クエリからキーワードを抽出
- WordPressでキーワード検索
- 28000文字単位で分割
- Qwen3に投入し回答
- 答えをQwen3で合成し終了
検索クエリからキーワードを抽出
今回はWordpressに対しては1個のキーワードだけで検索してみました(今後の改善点)。
Difyの「パラメーター抽出」ノードに以下のようなプロンプトを入力しました。
/no_think
検索に使う1単語だけ出力してください。複数ではなく一つの単語だけにするのが重要です。形容詞なども使わないでください。「会議室の予約方法を教えて」という文言に対して、
「会議室」と一つだけキーワードを返してくれます。
ちょっと長めでも、一番重要そうなワードを抜き出してくれたので、さすがだと思いました。
WordPressでキーワード検索
検索して、ヒットした前後400文字にフィルタリングしています。
またHTMLタグをすべて取り除き、
# [タイトル](URL)
## 内容
(内容)
## パンくず
親/子/孫というマークダウン形式にして、AIがわかりやすい形に整形しています。
(今回パンくずはあまり活用していません)
28000文字単位で分割
30kコンテキストなので、出力分を加味して28000文字を超えないように記事を連結させ、配列を作っています。実際には3万文字数ではなく3万トークン数ですが、ここでは特に気にしていません。
出力時にコンテキストサイズを超えてしまうと、失敗するかコンテキストシフトが発生してしまい、出力が壊れやすくなりますので、注意が必要です。
今回のpythonコードは以下のようにしました。ちょっと長いですが、やっていることはタグの除去と連結と、追加のフィルタリングです。もともと検索結果は対象キーワード前後の400文字&ある程度整形されて返すようにしていました。整形されていない場合はここでMarkdownやjsonなどに整形すれば問題ありません。
import re
def main(arg1, main_keyword, keywords) -> dict:
text_len = 28000
filter_patrs_num = 100
# タグを削除
text = remove_tags(arg1)
# "# "で分割
parts = ["# " + p if i > 0 else p for i, p in enumerate(re.split(r'(?<!#)# ', text))]
# フィルター
org_page_num = len(parts)
parts = filter_parts(parts, main_keyword, keywords, filter_patrs_num)
if arg1 == '一件もヒットしませんでした。':
parts = []
result = merge_parts(parts, text_len)
return {
"result": result,
"page_num": len(parts),
"org_page_num": org_page_num,
"arr_num": len(result),
}
def remove_tags(html: str) -> str:
result = html
# div, a
result = re.sub(r'<div.*?>|</div>|<a href.*?>|</a>', '', result)
# span
result = re.sub(r'<span.*?>(.*?)</span>', r'\1', result)
# mark
result = re.sub(r'<mark.*?>(.*?)</mark>', r'\1', result)
# \r\n -> \n
result = re.sub(r'\r\n', '\n', result)
# 単語圧縮
result = re.sub(r'パンくずリスト', 'パンくず', result)
# パンくずの" / "を"/"に変換して圧縮
result = re.sub(r'(?<=## パンくず\n).*?(?=\n)', lambda m: m.group().replace(' / ', '/'), result, flags=re.DOTALL)
return result
def filter_parts(parts, main_keyword, keywords, filter_patrs_num) -> list:
if len(parts) < filter_patrs_num:
return parts
out_parts = []
for part in parts:
for keyword in keywords:
# メインキーワードが含まれている場合は除外
if keyword in main_keyword:
continue
if keyword in part:
out_parts.append(part)
break
if len(out_parts) == 0:
return parts
return out_parts
def merge_parts(parts: list, text_len: int) -> list:
result = []
current_str = ""
for part in parts:
if len(current_str + part) < text_len:
current_str += part
else:
result.append(current_str)
current_str = part
if current_str:
result.append(current_str)
return result
Qwen3に投入し回答
以前のモデルに比べ、プロンプトに書けば聞いてくれます。今までは書いても無視が基本でしたので、一定のラインをついに超えたと思いました。聞いてくれるとなったら、あとは内容次第・・ということになります。(もちろんChatGPTのようなものと比べたらまだまだですが)
DifyのLLMノードの設定
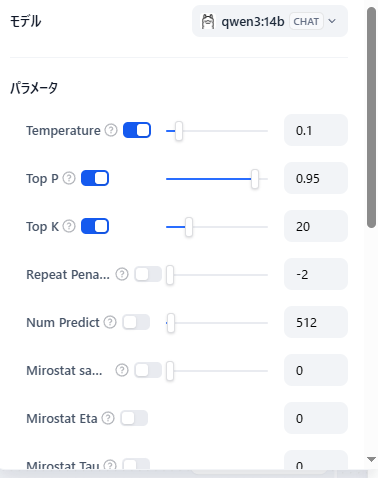
Top P、Top Kは公式の推奨値、Temperatureは創作をしないように「0.1」にしました。
プロンプトは入力テキストと、使用モデルとで微調整する必要があります。今回は微調整した結果こうなりました。まさにプロンプトエンジニアリングです。
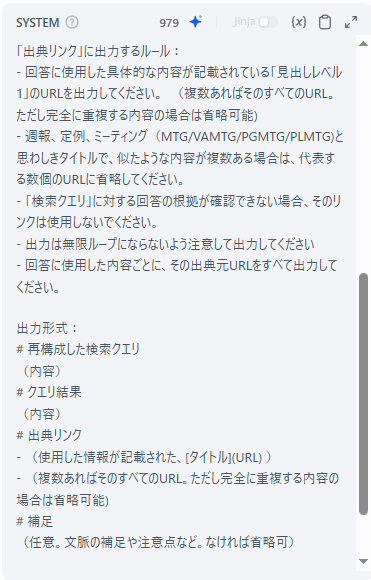
今回使用したプロンプト
/no_think
あなたは検索支援に特化したアシスタントです。ユーザーは検索クエリを入力しますが、その多くは曖昧または具体性に欠けるものです。以下の指針に従って、ユーザーの意図をくみ取り、より具体的で適切な検索クエリに変換してください。
- ユーザーはゲーム会社の一般社員です。
- 元のクエリの語彙・構文だけでなく、考えられる背景・目的・文脈を推測してください。
- 必要であれば補足情報を推定して検索意図を補完してください。
- あくまで「検索クエリ」として機能するように、簡潔かつ具体的に再構成してください。
「検索情報」は検索結果の情報です。この情報を元にユーザーの質問に答えてください。
- 「検索情報」に基づく情報のみを使って答えてください。
- 週報、定例、ミーティング(MTG/VAMTG/PGMTG/PLMTG)と思わしきタイトルの内容から参照する優先度は下げてください。
- 日付が古い方の優先度は下げてください。
- 即座に正確に答えてください。
- 分からないときは分からないと答えてください。
- 検索にヒットしなかった場合は見つからないと答えてください。
「出典リンク」に出力するルール:
- 回答に使用した具体的な内容が記載されている「見出しレベル1」のURLを出力してください。 (複数あればそのすべてのURL。ただし完全に重複する内容の場合は省略可能)
- 週報、定例、ミーティング(MTG/VAMTG/PGMTG/PLMTG)と思わしきタイトルで、似たような内容が複数ある場合は、代表する数個のURLに省略してください。
- 「検索クエリ」に対する回答の根拠が確認できない場合、そのリンクは使用しないでください。
- 出力は無限ループにならないよう注意して出力してください
- 回答に使用した内容ごとに、その出典元URLをすべて出力してください。
出力形式:
# 再構成した検索クエリ
(内容)
# クエリ結果
(内容)
# 出典リンク
- (使用した情報が記載された、[タイトル](URL) )
- (複数あればそのすべてのURL。ただし完全に重複する内容の場合は省略可能)
# 補足
(任意。文脈の補足や注意点など。なければ省略可)
検索情報:
{{#1748961567880.item#}}
け
結局たまに無限ループしてしまっていたので、その辺は今後の課題です。
答えをQwen3で合成し終了
いったんDify変数の配列に答えを格納しておき、最後にそれを投入してQwen3にまとめさせています。
以下際の際のプロンプトです
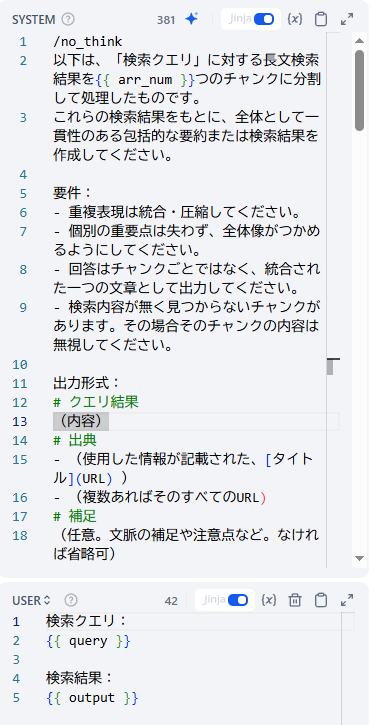
/no_think
以下は、「検索クエリ」に対する長文検索結果を{{ arr_num }}つのチャンクに分割して処理したものです。
これらの検索結果をもとに、全体として一貫性のある包括的な要約または検索結果を作成してください。
要件:
- 重複表現は統合・圧縮してください。
- 個別の重要点は失わず、全体像がつかめるようにしてください。
- 回答はチャンクごとではなく、統合された一つの文章として出力してください。
- 検索内容が無く見つからないチャンクがあります。その場合そのチャンクの内容は無視してください。
出力形式:
# クエリ結果
(内容)
# 出典
- (使用した情報が記載された、[タイトル](URL) )
- (複数あればそのすべてのURL)
# 補足
(任意。文脈の補足や注意点など。なければ省略可)全体像
以下今回組んだDifyのノードです。
jinja使った出力や空の時の分岐などでノードが増えてしまっていますが、やってることと言えば前述のステップだけですので、特に難しいことはしていません。
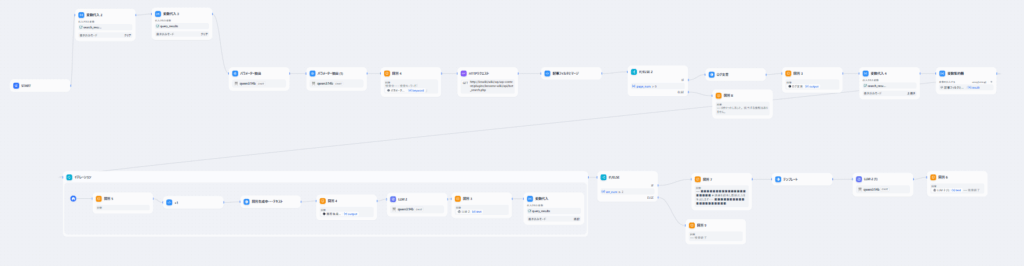
実行結果
よくある、Wikiの右下に吹き出しを作って呼び出せるようにしています。

最後に
今回の構築した検索システムは、そもそもWordpressへのクエリがキーワード検索だけだったりと、いろんな文章で検索をすると微妙な場合もあります。
得られた知見
今回は、
- 大雑把に検索
- AIでその中から必要な回答を得る
という2段構成で、主に2についての知見となり、得られたものには以下があります。
- 基本的に命令は守ってくれる
- 3万文字入力できる
- 嘘が減った。入力情報以外の知識を使うことが減った
指示に従ってくれるとなれば、あとはどう運用するか、組み上げるか次第なのかな、と感じました。
AIに入力できる許容量が増えたことで、大雑把検索でそこまで絞らなくてもいい感じの回答を得られました。ただ、大雑把検索のキーワードが悪すぎる場合はもちろんうまく回答できません。
今後の展望
時間があれば、記事に複数のEmbeddingをタグのように付けておいて、キーワードやタグ検索のようにEmbeddingで検索するようなのを試してみたいです。
以前は、200文字にたいして1Embeddingでマッチしたらそのテキストを採用、というもので、入力文書がぶつ切りになっていたり、必要な文書がマッチしなかったりしていました。
意味検索
「購入したアセットを探して」というクエリにしたいして「素材」と書いている記事にヒットさせたいです。
文章をEmbeddingもそうですが、キーワードのみをEmbeddingして、キーワードのみによる意味検索というものを試してみたいです。というのも、理由はわかりませんが、前回RAGを試したのですが、それよりも単にキーワード検索したほうが精度が良かったからです。
Wikiの内容が主に文章というよりは、セットアップ方法や操作方法などの単語に近い内容のものが多いからかもしれません。
30kは相当いろいろ出来る!
Gemma2で8kコンテキストの制限もありました。今回4倍に広がったことで、相当自由度が増えたと手ごたえがありました。そのキャラクターのゲーム内の全セリフを全部突っ込んだり、あらすじを全部突っ込んだりしてキャラボットを作るなども選択肢に入ってきます。
それでは今回はこの辺で。
\ 最新情報をチェック /