
C/C++ポインタ講座
プログラマーの尾関です。今回は、社内新人PG研修用に使用しているC/C++ポインタ講座について書きます。
ポインタはC/C++を勉強する際に重要な概念となりますので、学生さんなどC/C++を勉強中の方にお役に立てればと思います。
目次
- ポインタについて
- C/C++はメモリを操作する言語
- C言語には文字列型は存在しない
- ポインタは型である
- ポインタとアドレスの違い
- アドレスの操作
- 配列とポインタの違い
- ポインタ演算
- ヌルポインタ(nullptr)
- ポインタの配列
- 配列は「ポインタ」(=ポインタは危険、そして配列も危険)
- 関数呼び出し・戻り時のメモリの動き
- スタックメモリとヒープメモリ
- 動的メモリ確保
- 破棄に失敗するケース
- delete[] を使ったメモリの解放について
- メモリリーク
- まとめ
ポインタについて
ポインタ(C言語)は「プログラマが正しく扱える」という信頼を前提としている
ポインタは「プログラマが正しく扱える」という信頼を前提としています。そのためポインタに関する仕様を正しく理解して扱わなければなりません。逆に言うと「仕様を理解せず」「ミスをしやすい設計」をすると原因の特定困難な不具合が発生します。
Java, C#は安全な言語
C/C++の比較対象として、後発の言語である JavaやC#は配列の領域外参照(バッファオーバーラン)を言語仕様としてエラー検知できます。また、メモリの解放をガベージコレクションで行うことによって、メモリの破棄し忘れ(メモリリーク)や破棄済みのメモリアクセスを防いでいます。
C/C++はメモリを操作する言語
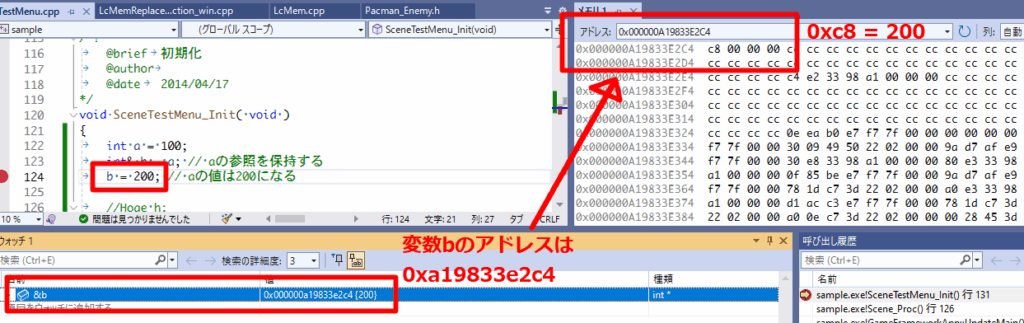
ポインタを理解するために、C/C++はメモリを直接操作する言語であることを知っておくと良いです。具体的にメモリの情報を見るには、実行中にブレークして、メニューから「デバッグ > ウィンドウ > メモリ」からメモリバイナリを表示すると、変数のアドレスから値を見ることができます。
C言語には文字列型は存在しない
例えば以下の定義は文字列リテラル "'Hero" へのポインタを定義しているだけです。
const char* PLAYER_NAME = "Hero";そのため「==」による比較では正しく判定をすることができません。
// この判定では文字列の一致を判定できない.
if(pStr == "abc") {
// 判定できない.
この比較は、pStr と "abc" という2つの文字列リテラルの先頭アドレス(ポインタ)が一致するかどうかを判定しているだけであり、文字列の内容が一致しているかどうかは判定できません。
文字列の内容が一致しているかどうかを判定するには、strcmp 関数を使います。
// strcmpを使うことで文字列の一致が判定できる
if(strcmp(pStr, "abc") == 0) {
// 文字列が一致.ポインタは型である
ポインタは「型」の1つです。
int型、char型、float型と同様に、それぞれのポインタは int*型、char*型、flaot*型となります。
ポインタは型なので、ポインタ型の変数もポインタ型の値もあります。
ポインタとアドレスの違い
問題:ポインタとアドレスの違いを説明してください。
- ポインタ:メモリの番地を格納する変数
- アドレス:メモリ領域の場所を表す値
アドレスの操作
変数には「&」をつけることでアドレスを取り出すことができます。ポインタには「*」をつけることで値を取り出すことができます。
int hoge = 5;
int* p = &hoge; // 変数のアドレスを取り出す
*p = 10; // ポインタから値を取り出す
配列とポインタの違い
- 配列:連続したメモリ空間
- ポインタ:メモリの番地を格納する変数
int arr[4] = {};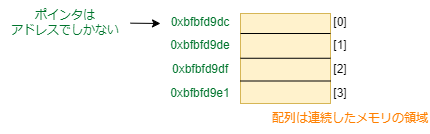
配列で宣言すると要素数が確定する
配列はコンパイル時にサイズが確定するため、以下の記述でサイズを取得できます。
int arr[3] = {};
// 配列はsizeofを使うことでサイズが求められる.
int size = (sizeof(arr) / sizeof(arr[0]);ただし、このポインタを関数にポインタとして渡した場合は、サイズは不明となります。
ポインタ演算
問題:以下のprintにより出力される値は?(*pArr2の値は何か?)
char arr[8] = {0, 1, 2, 3, 4, 5, 6, 7};
int* pArr = (int*)&arr;
pArr++;
char* pArr2 = (char*)pArr;
LC_DBG_PRINTF("%d", *pArr2);正解:4
ヌルポインタ(nullptr)
以下のコードがエラーとなる理由について説明してください。
int* p = nullptr;
*p = 100;ポインタの配列
①、②、③のうちプログラムで停止となる部分は何番か?
int* arr[3][2] = {};
LC_DBG_PRINTF("%x", arr[1][1]); // ①
arr[1][1] = (int*)0xFFFFFFFF; // ②
*arr[1][1] = 1; // ③配列は「ポインタ」(=ポインタは危険、そして配列も危険)
配列の要素アクセスは危険なので、できるだけ直接参照を避けるようにします。具体的には領域外チェックを入れた関数を通して取得するようにします。これにより領域外参照を避けることができます。
const int MAP_WIDTH = 12;
const int MAP_HEIGHT = 12;
static int s_Map[MAP_WIDTH][MAP_HEIGHT] = {};
// マップデータを取得する.
int GetMap(int x, int y) {
// 領域外チェック.
if(0 < x || x <= MAP_WIDTH) {
return -1; // 領域外.
}
if(0 < y || y <= MAP_HEIGHT) {
return -1; // 領域外.
}
return s_Map[y][x];
}配列の領域外のメモリに書き込んだ場合はどうなるのか?
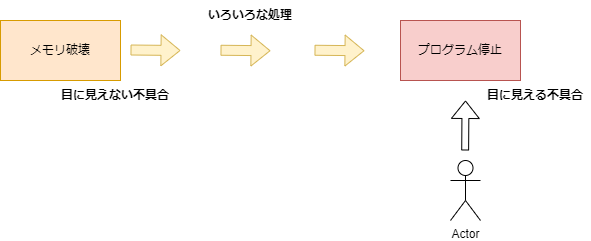
(メモリ破壊による不具合は遅れてやってくることがあります…)
例えば以下のコードは、処理系によっては有効なアドレスとなり、メモリ破壊をしても正常に動作する可能性があります。
class Hoge {
int a[5];
int b;
};
Hoge hoge = {};
// 値は Hoge.b に書き込まれることが多い (※処理系依存).
// 有効なメモリ領域であればハングしない可能性はありますが、
// オーバーランによりメモリを壊していると言えます.
hoge.a[5] = 10;ライブラリが提供しているクラスを使ってバッファオーバーランを防ぐ
std::array、UEならTArrayなど、ライブラリやゲームエンジンが提供している配列・リストを使うことで、バッファオーバーランやメモリ操作周りのエラーをある程度防ぐこともできます。
static_assert()でバッファオーバーランを防ぐ
static_assert() で配列のサイズをチェックすると、コンパイル時にサイズオーバーを検知することができます。
関数呼び出し・戻り時のメモリの動き
関数呼び出し時の「引数」returnでの戻り時の「戻り値」は基本的に「コピー」となります。
この「コピー」の挙動を正しく理解する必要があります。
引数は値渡し
例えば以下のコードでは、変数 x, y, a, b はそれぞれ別のメモリ領域に配置されます。
void func(int a, int b) {
a = 100;
b = 200;
}
void main() {
int x = 1;
int y = 2;
func(x, y);
}変数x, y は 関数func() を呼び出したときに引数 a, b にコピーされます。このことを「値渡し」と呼びます。
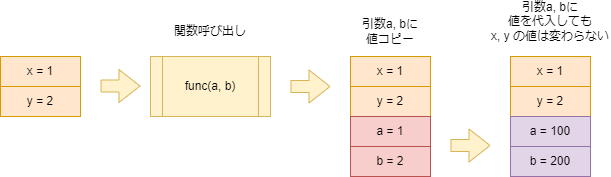
引数の値を書き換えても元の値が書き換わらないのはこのことが原因です。
戻り値はコピー
以下のコードにおいて、fuuc内で定義した変数cは戻り値で返したときに、コピーされ変数zに代入されます。
int func(int a, int b) {
int c = a + b;
return c;
}
void main() {
int x = 100;
int y = 200;
int z = func(x, y);
}ポインタを戻り値するのは危険
問題:以下のコードが危険である理由を説明してください。
int* func(int a, int b) {
int arr[2];
arr[0] = a;
arr[1] = b;
return arr;
}スタックメモリとヒープメモリ
問題:以下のメモリはそれぞれどちらに格納されるか。
- ローカル変数:
- コールスタック:
- グローバル変数:
- malloc() や new演算子によって確保されたメモリ:
メモリ領域には他にも「静的領域」と「テキスト領域」があります。(static変数は静的領域に確保されます)
■答え
- ローカル変数: (スタック・スコープ依存・自動変数)
- コールスタック: (スタック・スコープ依存)
- グローバル変数: (静的領域・コンパイル時にサイズが確定)
- malloc() や new演算子によって確保されたメモリ: (ヒープ領域・プログラムによる手動制御)
動的メモリ確保
動的メモリ確保とは、「プログラムの実行中に必要なタイミングで必要な量のメモリを確保すること」です。これにより、配列やオブジェクトのサイズを実行時に決定できるなど、柔軟なメモリ管理が可能になります。結果として、必要以上のメモリを確保せずに済むため、メモリの効率的な利用につながる場合もあります。
一方で、固定サイズの配列を使う場合は、コンパイル時にサイズが決まり、プログラムの実行中に追加のメモリ確保や解放(new/delete)は不要です。このような設計では、手動でメモリを解放し忘れることがないため、メモリリークのリスクが低くなります。
メモリリークを防ぐためには、new/deleteを直接使わない設計(固定配列やスマートポインタの利用)が有効です。C++では、スマートポインタ(std::unique_ptrやstd::shared_ptr)を使うことで、動的メモリの自動管理も可能です。
ただし、固定配列はサイズが変更できないため、より柔軟なメモリ管理が必要な場合は動的メモリ確保が不可欠です。
また、Unreal EngineのAActorのように、エンジン側がオブジェクトの破棄を自動で行う仕組みがある場合、ユーザーが明示的にdeleteを書く必要がなく、メモリリークのリスクを低減できます。
CとC++でのメモリ確保方法の違い
- C言語: alloc() / free()
- C++:new, new [], delete, delete[]
動的メモリ確保とは
ヒープ領域の中から空いているメモリの部分を確保し、その先頭アドレスを返すことです。破棄を行う場合には「先頭アドレス」を指定する必要があります。
allocとnewの違い
- alloc: 指定したメモリサイズを確保する
- new: 指定したデータ型のサイズを確保する。配列のサイズを指定してメモリ確保ができる。構造体やクラスの場合にはコンストラクタが呼び出される
freeとdeleteの違い
- free: 指定したアドレスのメモリを破棄する
- delete: 指定したアドレスのメモリを破棄する。newのとき配列で確保した場合は delete[] で消さなければならない。構造体やクラスの場合にはデストラクタが呼び出される
破棄に失敗するケース
メモリ破棄に失敗するケースとして、多くの場合は以下の2つがあります。
- 破棄済みの(無効な)メモリを開放しようとすると停止が発生します。(二重開放)
- 動的メモリ確保した領域でないメモリを free() / delete で破棄しても停止が発生します
よってメモリ破棄時にはアドレスを無効(nullptr)にしておくと良いです。
Hoge* pHoge = new Hoge();
delete pHoge;
pHoge = nullptr; // アドレス参照を消しておく.delete[] を使ったメモリの解放について
delete[] は配列の動的メモリ確保を行った時の解放処理として使用します。
int* arr = new int[3];
arr[0] = 100;
arr[1] = 200;
arr[2] = 300;
delete[] arr;
arr = nullptr;よって以下の使い方は正しくありません。
int* arr[3] = {};
arr[0] = new int(100);
arr[1] = new int(200);
arr[2] = new int(300);
delete[] arr;メモリリーク
メモリリークが発生するのは以下の要因が考えられます。
- 「new」だけ書いて「delete (メモリ解放)」を書き忘れる
- 予期せぬフローで「delete」が呼び出されず、メモリが確保されたままになってしまう
「2」については処理の流れをしっかり理解する必要がありますが、少なくとも「1」についてはケアレスミスです。ケアレスミスを回避するには、new するときは「new と delete をセットで書く」ということを忘れずに行うと良いです。
まとめ
ポイント
- C/C++のポインタは「危険」であると認識する
- その上で「安全」に扱う方法を知る
- メモリの動きを意識しながらコードを書く
- アドレスが何を指しているのかを考えながらコードを書く
補足:参照(C++)
C++では変数宣言や引数や戻り値に参照を表す「&」を指定できるようになりました。
参照を指定すると、変数はコピーではなく「参照(メモリを共有)」できます。
int a = 100;
int& b = a; // aの参照を保持する
b = 200; // aの値は200になる参照渡しにすることで、巨大なクラスや構造体を引数をメモリコピーすることなく、高速で渡すことができます。
補足:constキーワード
値が変更されないことを保証する場合、constキーワードを付けることで安全に値を宣言したり、値を渡すことができます。例えば引数が const 参照の場合、クラスを渡しても値が書き換わらない保証が得られるので、安心してクラスを渡すことができます。
\ 最新情報をチェック /
