Ryzen AI Max+ 395(EVO-X2)でgpt-oss-120bを動かしてみた
Ryzen AI Max+ 395(EVO-X2)とは?
※CPU名を356と間違えて記載しておりました。正しくは「Ryzen AI Max+ 395」です。
プログラマーの石戸です。
先月OpenAIからオープンソースモデルのgpt-oss:20b / 120bが公開され、AI界隈をずっと牽引してきた大手が久しぶりのオープンソースのAIを出すということで非常に盛り上がっておりました。gpt-oss-20bは16GBのVRAMにすべて入り、推論も高速です。ただし120bは60GBほどあり気軽に動かせるものではありません。そんな中、Ryzen AI Max+ 395を搭載したEVO-X2というミニPCで"動かした!"という人をちらほら見かけました。(検証や投稿は貴重でとても参考になりました。ありがとうございます。)
そこでEVO-X2が気になったので調べてみると、ユニファイドメモリ(スマホやマックブックなどのようにCPU/GPUでメモリを共有する)を採用した128GBメモリでおおよそ30万円でした。メモリの多さから考えると破格です。もちろんこのミニPCでAIがクラウドサービスのように動くのであればNvidiaの株は急落しているはずですので、そこまでの期待は禁物です。ですが開発マシンとそんなに差が無い価格帯で、gpt-oss-120bの検証できるのであればやってみたなということで、社長に聞いてみたら快くOKを頂きました。
Ryzen AI Max+ 395を搭載したモデルは何個かありました。当時調査した限りですと日本向けに販売しているのはこのEVO-X2とHPのノートPCのみでした。ノートPCは必要なかったのと、EVO-X2は日本のAmazonでAmazon倉庫からの発送で注文できるようだったのでEVO-X2に決めました。在庫をウォッチしてすかさず社長にポチってもらいました。今はまだ業務として検証しているわけではなく趣味の範囲を超えないため「風が吹けば桶屋が儲かる」かのように、この記事によって巡り巡ってEVO-X2分の効果が出ると信じて執筆いたします。
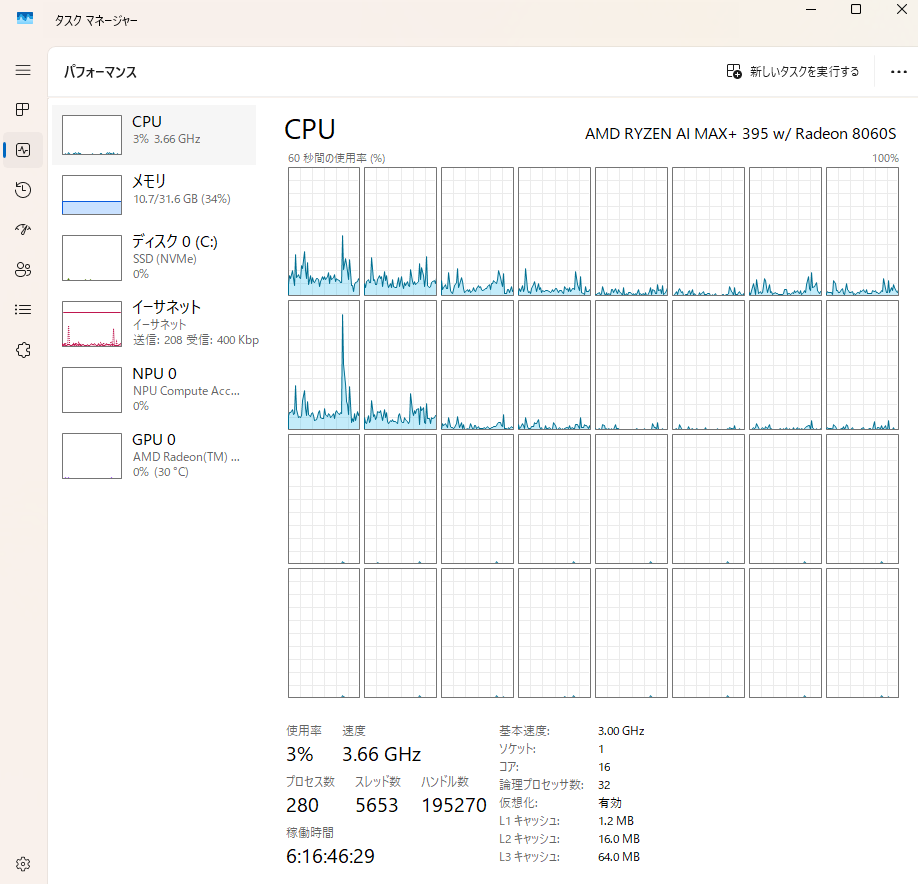
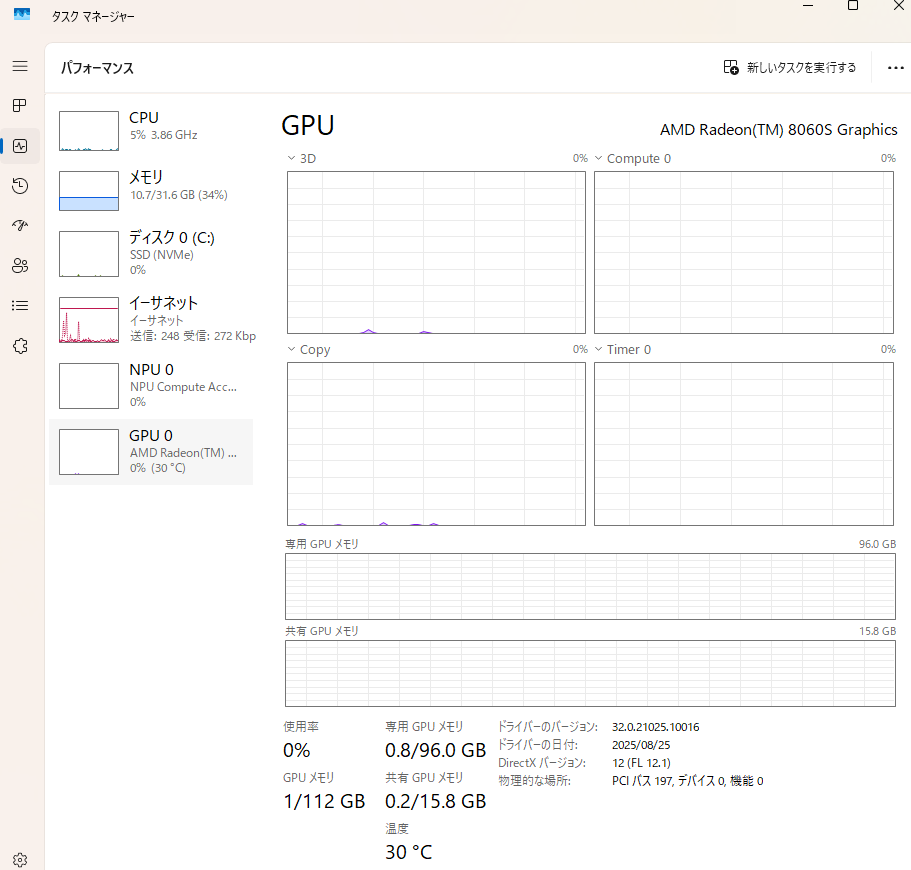
せっかくなのでEVO-X2のタスクマネージャの画像を載せます。メモリもCPUスレッド数も普段のPCよりとても多く搭載されていて感動します。ちなみに最適化が進んだせいかWidowsのllama.cpp-vulkanでもかなり良いパフォーマンスが出たためWindowsを使っています。Ubuntuは経験が浅くデュアルブートしようかどうしようかと悩んでいたところだったので良かったです。また、電力設定はデフォルトのバランス設定です。パフォーマンス設定ではさらに1割ほど性能が上がると検証していた人がいましたが、熱が怖かったので据え置きにしました。この暑い中、推論中は90度に達しないぐらいの温度でした(今日は外が23度程度と寒いせいか、70度も超えません)思ったより熱の心配は大丈夫そうで、ミニPCの箱自体を触るとヒヤリする素材なので排熱は結構気を使って作られているのかもしれません。ファンの音に関しては近くに超うるさいサーキュレータがあるので気になりません・・。
バックエンドプロバイダ llama-sever
まず今回の検証の環境ですが、前回のAI記事を書いたときと少し変わっており、今回はllama-serverを使います。ローカルAIを動かすプロバイダーとしてよく名前に上がるのが、Ollama、LmStduio、vLLM、llama-serverで、それぞれの説明を軽くします。
Ollama
この中でOllamaは初心者向けに設計されており、非常に簡単に動作させることが出来ます。私もOllamaを使って知識が増え大変お世話になりました。ただOllamaの動作パフォーマンスを他と比較したところだいぶ差がありました。コミュニティのパフォーマンスについて触れているスレッドでは、利便性を優先していると言っていたので、プロジェクトの方針によるものだと思います。
Ollamaのバックエンドはllama.cpp(≒ggml)で出来ていますがここまでパフォーマンスに差が出るのはちょっと不思議です。フロントエンドは年初ぐらいにGo言語で書き換えられていました(確かにGo言語は楽そうだなぁ)。初めて触るなら断然Ollamaですが速度を突き詰めたい場合他を選ぶのはありです。
LmStudio
少し前は個人のみ無料だったようですが私が触ろうと思ったときには企業も無料利用可能になったようでした。もしかしたらフリーになったことで目につきやすくなったのかもしれません。触ってみるとUIもよくできていて、モデルのダウンロードも非常にお手軽でした。ただしllama.cppの「--n-cpu-moe」相当のオプションが無く、出来るだけVRAMにモデルを載せることが出来ないようでしたので採用を見送りました。しっかりVRAMを使い切ることでパフォーマンスが全く違います。
LmStduioもバックエンドはllama.cppを使っているようですが、どのぐらいカスタマイズしているかは確認していません。
vLLM
こちらは触ってみたかったのですが時間が取れず全く調査できていません。早いのか遅いのかも分かっていません。
llama-server
llama.cppプロジェクト内で実装されているサーバーです。Ollamaと比べて動作パフォーマンスが良く、オプションも豊富です。前回の記事を書いたときには、まだexampleフォルダに入っていて推論サーバの実装例という位置づけでした。現在ではToolsフォルダに入っており、対応は以前に比べより前向きなのではと思っています。その生い立ちのせいか数々のフロントエンドサービスでOllamaの選択項目は有りますが、llama-serverで動かすマニュアルはあまり見かけません。しかしその場合でもOpenAI互換として登録すれば動きます。
「--n-cpu-moe」オプションは少ないVRAMにモデルがすべて乗らない場合に最適な調整をすることが出来ます。例えば、gpt-ossやQwen3-30B-3AなどのMoEモデルは、MoE部分をCPUにすることでパフォーマンスをなるべく保ちながら推論させることが出来ます。この設定は一括ですべてCPUにするのではなく、CPUで何個のMoEを動かすか指定できます。Ollamaなど、バックエンドの細かいオプションはそのプロジェクトの方針によって調整できない場合があります。私もRTX 4070でgpt-ossがここまで高速に動くとは思っていませんでした。
gpt-oss-20bの実行パフォーマンス
まずは基準として手元でもともと触っていたRTX 4070(12GB)の速度を載せます。残念ながら16GBのVRAMを積んだGPUが手元に無いため、VRAMにすべてが収まらない12GBのVRAMでのテストになりますが、12GBのミドルスペックを持っている方は多いと思いますので参考になる方が居れば幸いです。
また、基本的にフラッシュアテンションはオンで問題なさそうですが、ベンチではオフで計測している方も多いので両方取っています。
RTX 4070
llama-bench
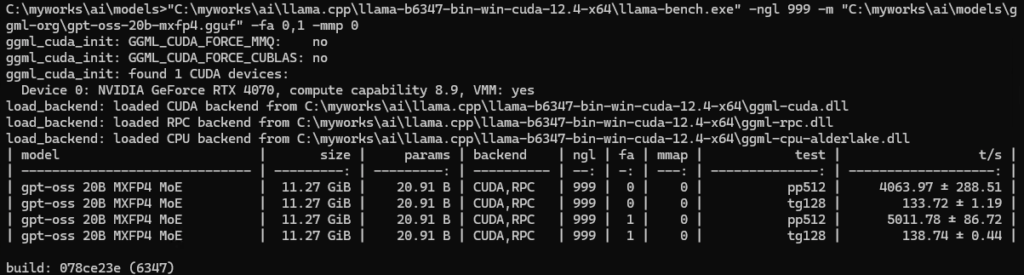
pp=5000/tps、tg=138/tpsも出ています。(pp=プロンプト処理、tg=テキスト生成)
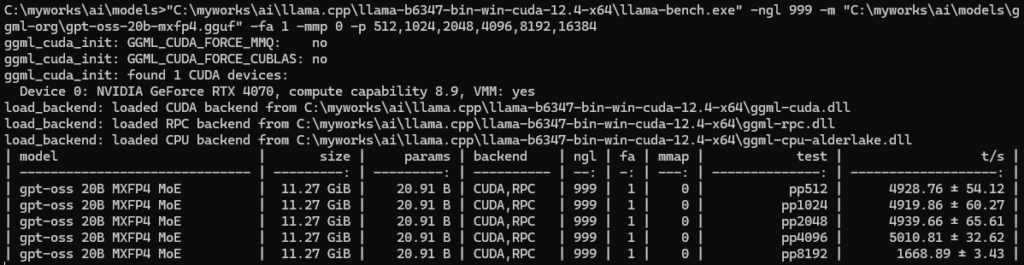
プロンプトを増やしました。どうやらpp8192はメモリから溢れたようで急激に遅くなっています。16384は処理が返ってこなかったので中断しました。
5000!?と衝撃でした。さすがNvidia、さすがOpenAI、さすがllama.cppと思いました。ハードからフロントエンドまですべてそろってこのパフォーマンスが実現されてるんだと再認識しました。
llama-benchでは--n-cpu-moeが指定できませんのであとは実測を行います。
実測 コンテキストサイズ8k
llama-cli.exe --no-mmap --jinja --reasoning-format none -ngl 999 -fa on -m ".\ggml-org\gpt-oss-20b-mxfp4.gguf" -c 8192 --temp 1.0 --top-p 1.0 --top-k 0 --min-p 0.01 --repeat-penalty 1.05

pp=4088/tps、tg=104/tps
パラメータに関して:redditでおススメしている人がいたので、公式推奨値のmin-p 0からmin-pを0.01に上げています。これすることでサンプリングタイムが数秒かかってものがだいぶ短くなりました。(※正確なアルゴリズムは見ていませんので間違っていたらすみません。見た限りだと、サンプリングはCPUで全語彙に対して、様々なアルゴリズム(top-pやtop-kなど)のフィルタリングやソートを順に掛けていきます。gpt-ossは20万越えの単語がありますので、計算コストは無視できません。そこでまずmin-pでフィルタリングすることで早くなるのではないかと思いました。)
実測 コンテキストサイズ64k
12GBのVRAMに収まらないので--n-cpu-moe 4にしています。
llama-cli.exe --no-mmap --jinja --reasoning-format none -ngl 999 -fa on -m ".\ggml-org\gpt-oss-20b-mxfp4.gguf" -c 65536 –-n-cpu-moe 4 --temp 1.0 --top-p 1.0 --top-k 0 --min-p 0.01 --repeat-penalty 1.05

pp=2030/tps、tg=46/tps(ちなみに、8kトークンのプロンプトだとpp=2911/tps, tg=61/tpsでした)
実測 コンテキストサイズ128k
12GBのVRAMに収まらないので--n-cpu-moe 8にしています。
llama-cli.exe --no-mmap --jinja --reasoning-format none -ngl 999 -fa on -m ".\ggml-org\gpt-oss-20b-mxfp4.gguf" -c 131072 –-n-cpu-moe 8 --temp 1.0 --top-p 1.0 --top-k 0 --min-p 0.01 --repeat-penalty 1.05

pp=1250/tps、tg=30/tps(ちなみに、8kトークンのプロンプトだとpp=1841/tps、tg=44/tpsでした)
64kコンテキストサイズでの動作速度がpp=2k/tpsとtg=46/tpsですので、60kプロンプトを食わせても30秒程度で出力され始め、30tpsを超えていれば読む分には十分な速度が出ます。コードの出力では50tpsあると嬉しいですがそれでも十分です。
昨今のエージェントですと、32kはすぐに使い切りますが、64kだと結構動いてくれます。例えばRooCodeなどのエージェントのプロンプトはおおよそ10kトークン、1000行のソースはおおよそ10kトークンぐらいあります。つまり2ソース添付するだけで32kを使い切ってしまいますが、逆に64kあればそれなりに処理できるということです。よって今回は64kが実用的なラインとします。(そのぐらいで動くようにエージェントが賢くコンテキストを使いまわしているんだろうなと使っていて感じました)
RooCodeはソースに行番号を付けてLLMに入力しています。そしてモデルが吐き出すコードを編集部分のみにすることで、最小限の出力(&精度)と高速なマージを実現しているようです。Continue.devは行番号は付けておらず、実際にモデルの出力が安定しなかったりマージがうまくいかなかったりします。行番号の分だけトークンをかなり消費してしまいますが、精度の向上には一躍かっているようで、参考になります。
RTX 4070はgpt-oss:20bを動かす分にはとてもパワフルなことがわかりました。では本題のEVO-X2はどうでしょう。
EVO-X2(Ryzen AI Max+ 395)
llama-bench
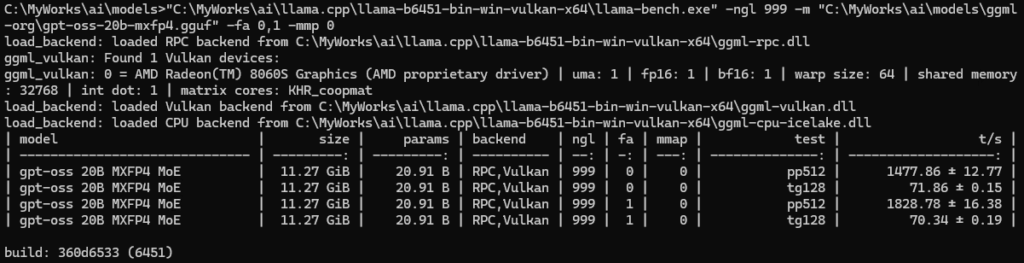
ppは1828/tps、tgは70/tps出ています。(pp=プロンプト処理、tg=テキスト生成)
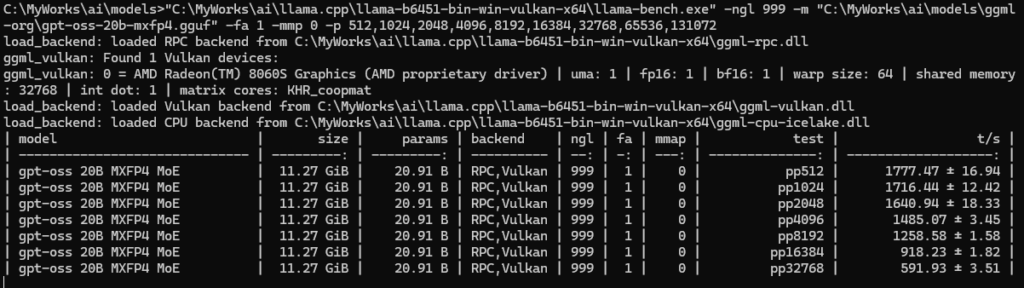
プロンプトを増やすと、どんどん速度が遅くなっていき、32kではpp=591/tpsしか出ていません。処理が返ってこなかったので中断しました。
32kプロンプトの処理はおおよそ1分かかります。64kプロンプトではその倍以上かかりますし、128kプロンプトの処理では10分待つ、となってしまうと128kは到底使える速度ではありません。(ロングプロンプトではGPUの負荷がほぼない状態でも電力消費は有りましたのでおそらくメモリ帯域がボトルネックなのではないかと思いますが、計測の仕方がわからず自信をもって断言できません)
とはいえpp512が1800/tps程度出ています。発売当初から数々のアップデートが入っているようで、ドライバやllama.cpp側の最適化には凄いの一言です。
では実際にllama-cliでのパフォーマンスを見ていきましょう。
実測 コンテキストサイズ8k
llama-cli.exe --no-mmap --jinja --reasoning-format none -ngl 999 -fa on -m ".\ggml-org\gpt-oss-20b-mxfp4.gguf" -c 8192 --temp 1.0 --top-p 1.0 --top-k 0 --min-p 0.01 --repeat-penalty 1.05

pp=1407/tps, tg=61tps
実測 コンテキストサイズ64k

pp=356/tps, tg=34tps
実測 コンテキストサイズ128k
↓6kプロンプト

↓60kプロンプト

コンテキストサイズ64k時のものとほぼ速度差が無く、コンテキストサイズが増えたからと言って速度は変わりませんでした。つまり入力するプロンプトの量に依存してプロンプト処理速度が変わります。
gpt-oss:120b
ようやく本題です。EVO-X2では120bが動作するというのが大きなポイントです。
llama-bench
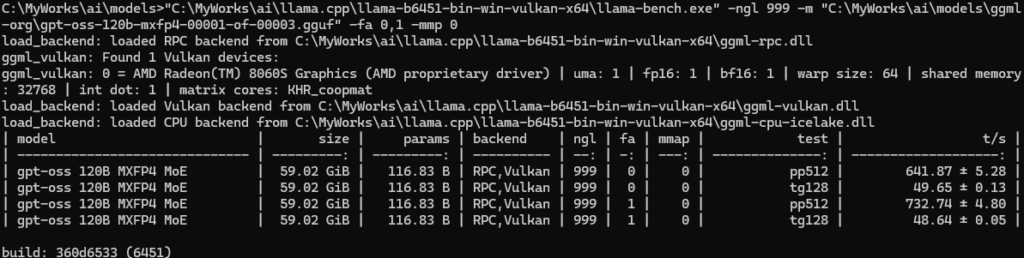
pp=732/tps, tp=48/tps(pp=プロンプト処理、tg=テキスト生成)
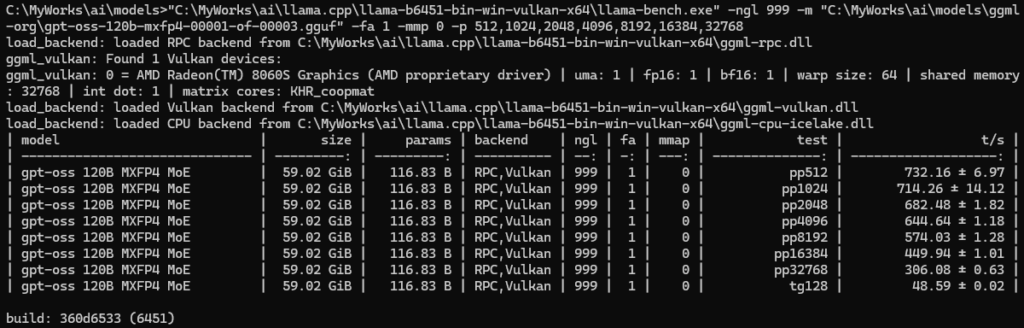
20bの時と同様にパフォーマンスが下がっていき、32kではpp=306/tpsに。
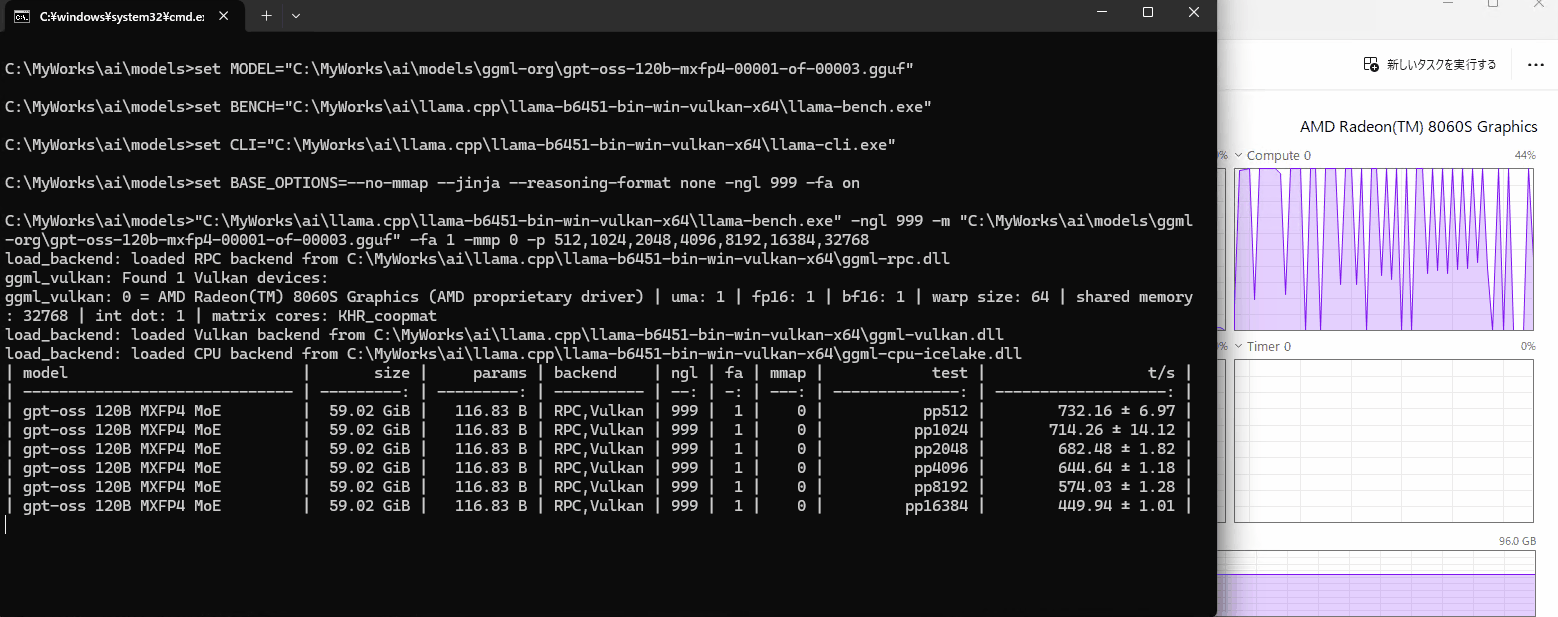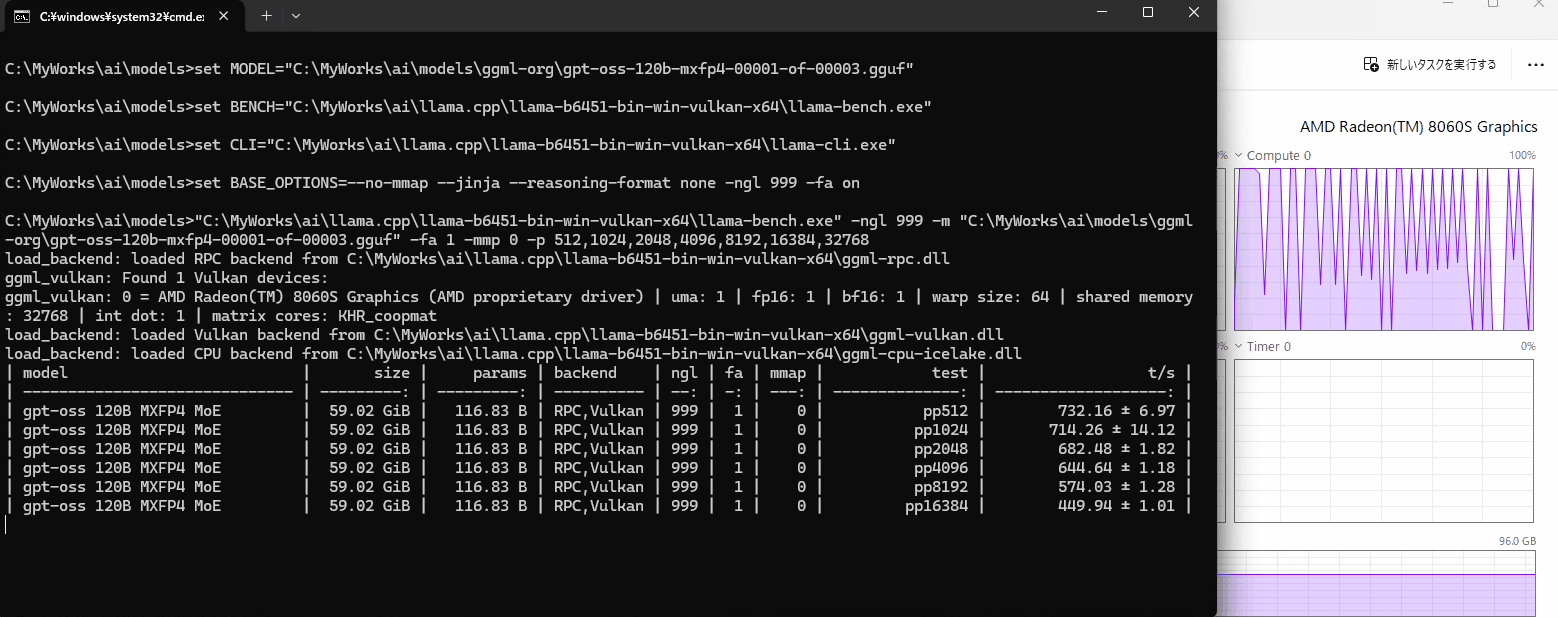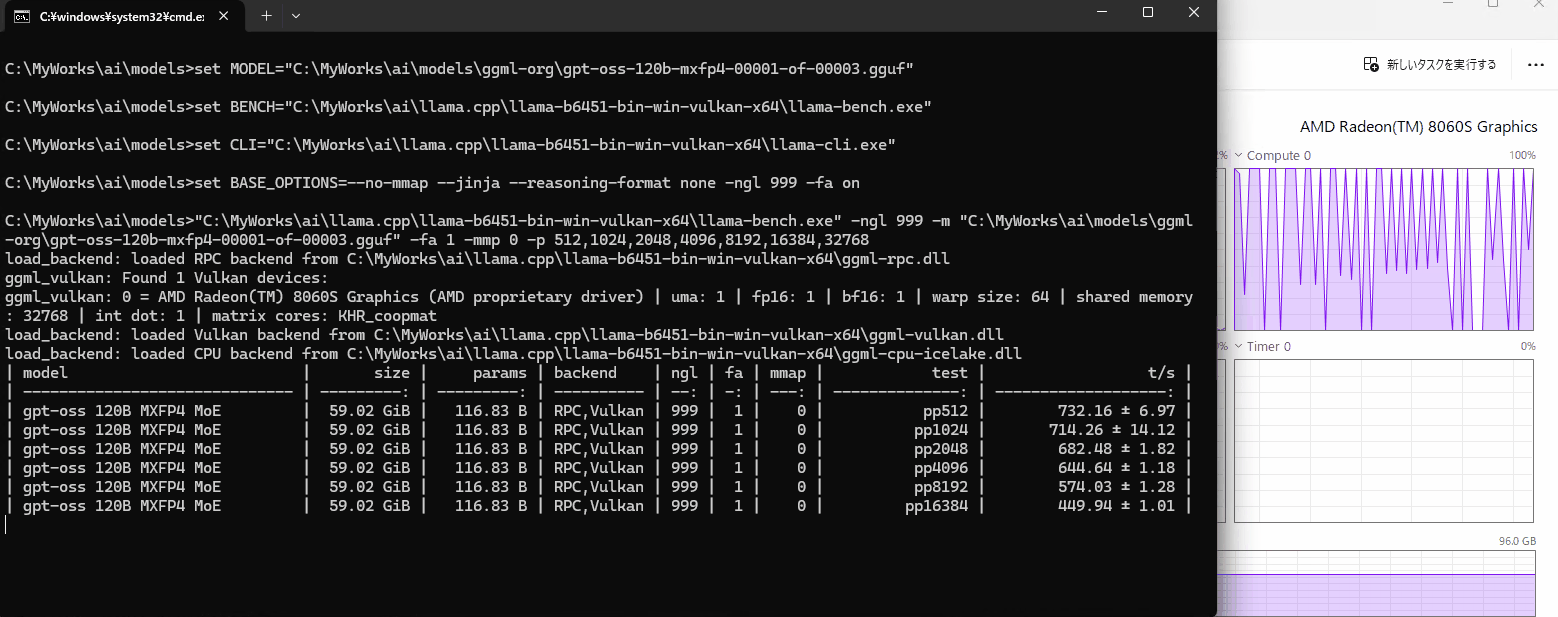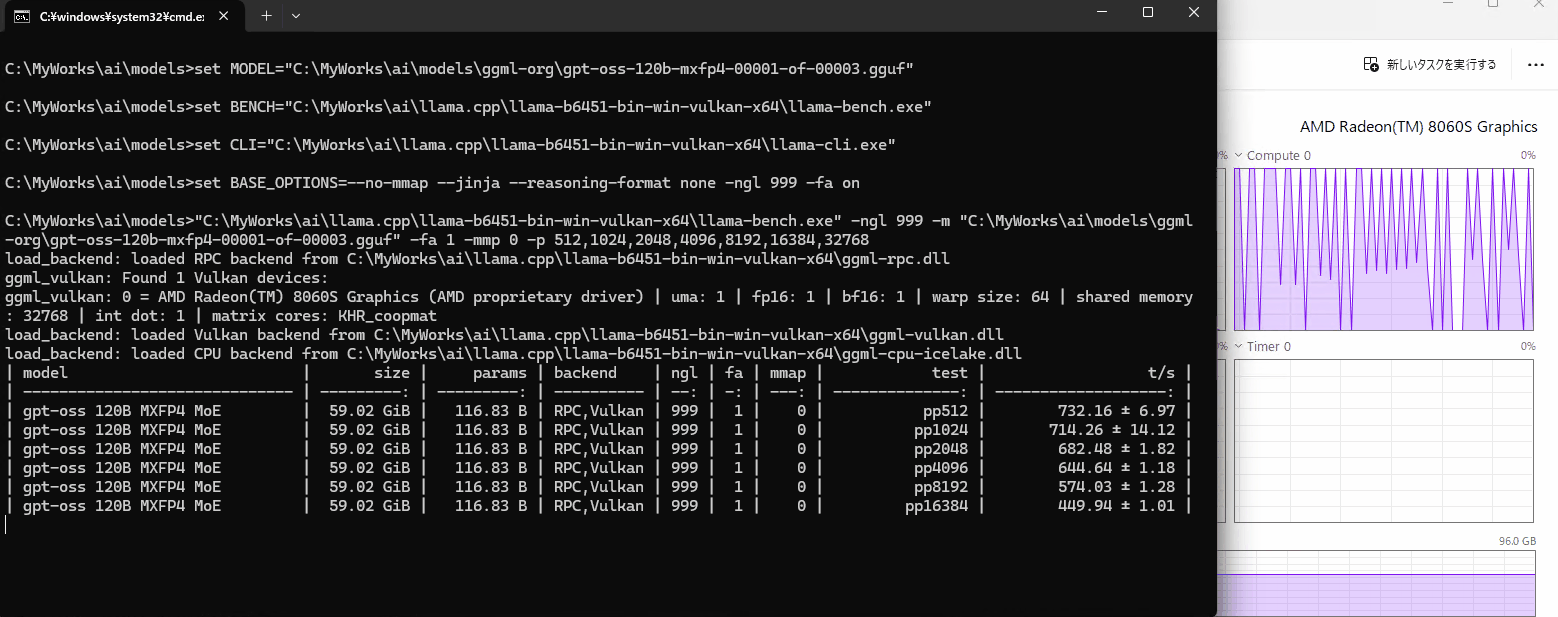
このGIFはpp32768処理中のGPU負荷です。pp8192ぐらいですとGPU負荷が休んでいるタイミングが無くずっと処理しているようでしたが、どこかが詰まってGPUがたびたび休んでます。
比べるとプロンプト処理が大きく遅いですが、テキスト生成速度は性能から考えるとかなり早いです。
実測 コンテキストサイズ64k
プロンプトは鬼滅の刃Wikiの冒頭部分をコピーして、要約して とお願いしています。
128kは遅すぎて実質使う機会がないので64kにしています。
llama-cli.exe --no-mmap --jinja --reasoning-format none -ngl 999 -fa on -m ".\ggml-org\gpt-oss-120b-mxfp4-00001-of-00003-.gguf" -c 65536 --temp 1.0 --top-p 1.0 --top-k 0 --min-p 0.01 --repeat-penalty 1.05
↓6kプロンプト

pp=603/tps tg=32/tps
10秒程度で出力され始め、出力速度も読む速度ぐらい出るのでそこまで遅く感じません。
↓30kプロンプト

pp=332/tps tg=24/tps
ppが半減しているので、プロンプトが長くなると倍増して時間がかかります。今回は30kプロンプトで出力が開始され始めるのに86秒かかりました。6kプロンプトに比べ5倍程度のプロンプトなのに時間は9倍かかっていますので、体感としても思ったより出力され始めるのが遅い、と感じます。
↓60kプロンプト

pp=195/tps tg=19/tps
ppがさらに遅くなり、プロンプトが長くなったのと相まって、60kプロンプトで出力され始めるのに5分かかっています。30kの時よりさらに3倍以上かかっていますし、コーヒーを淹れてきてもまだ終わりません。何かの処理ツールなどなら問題ないでしょうが、質問などの用途ではかなり厳しいです。ただし、それでもテキスト生成速度が19/tpsもあるのが驚きです。
実際の出力時の様子
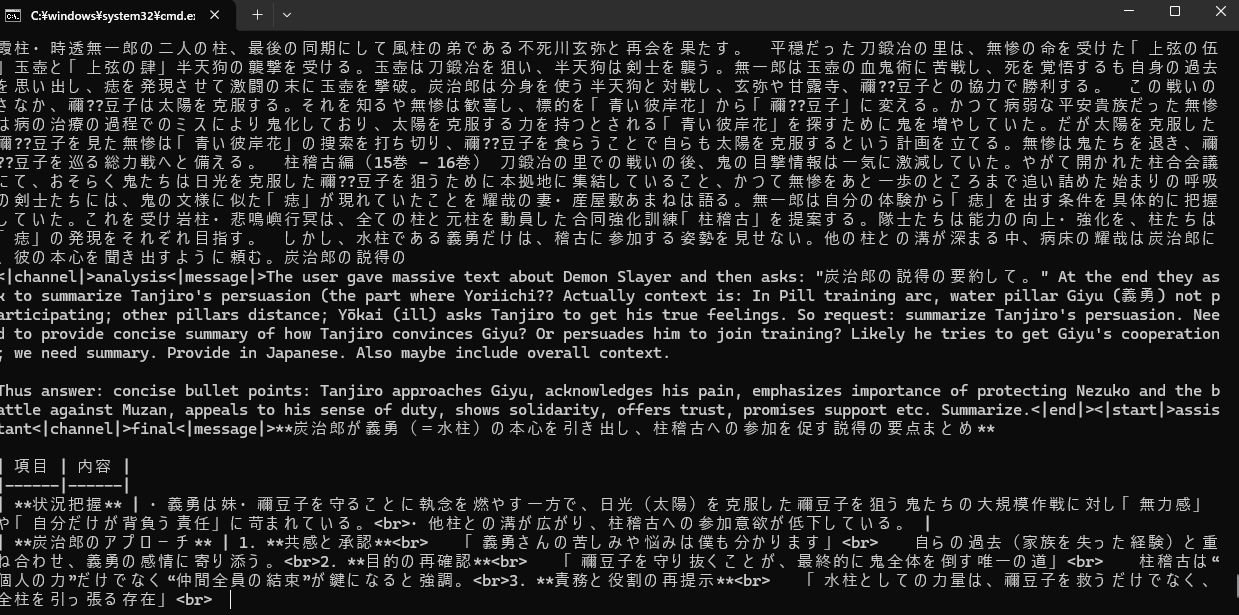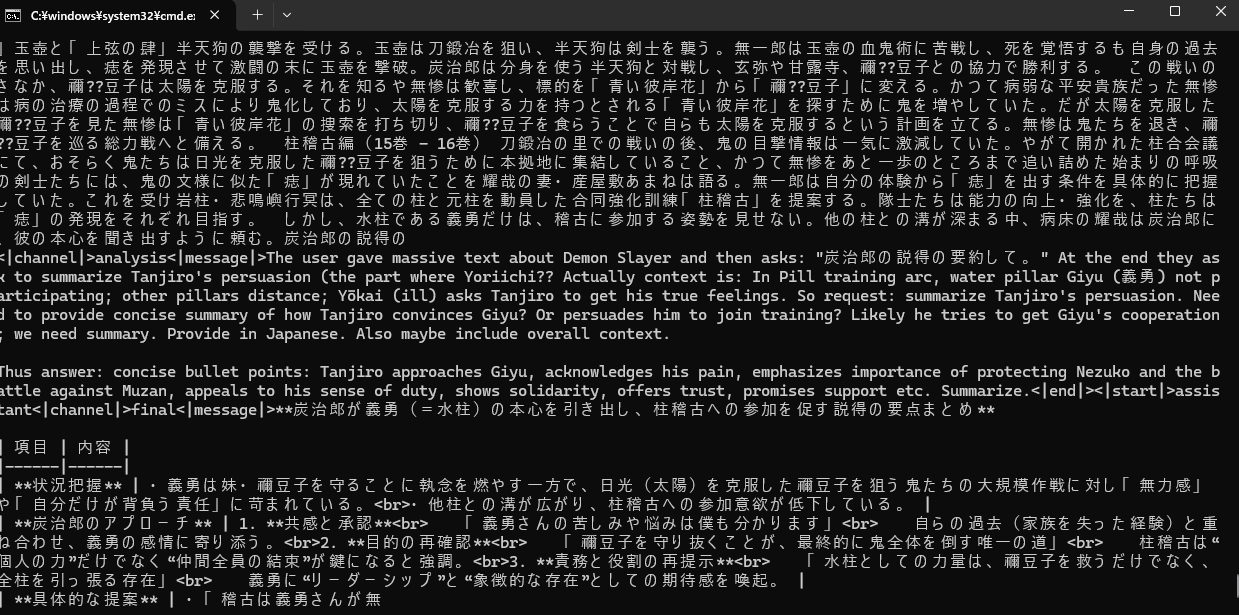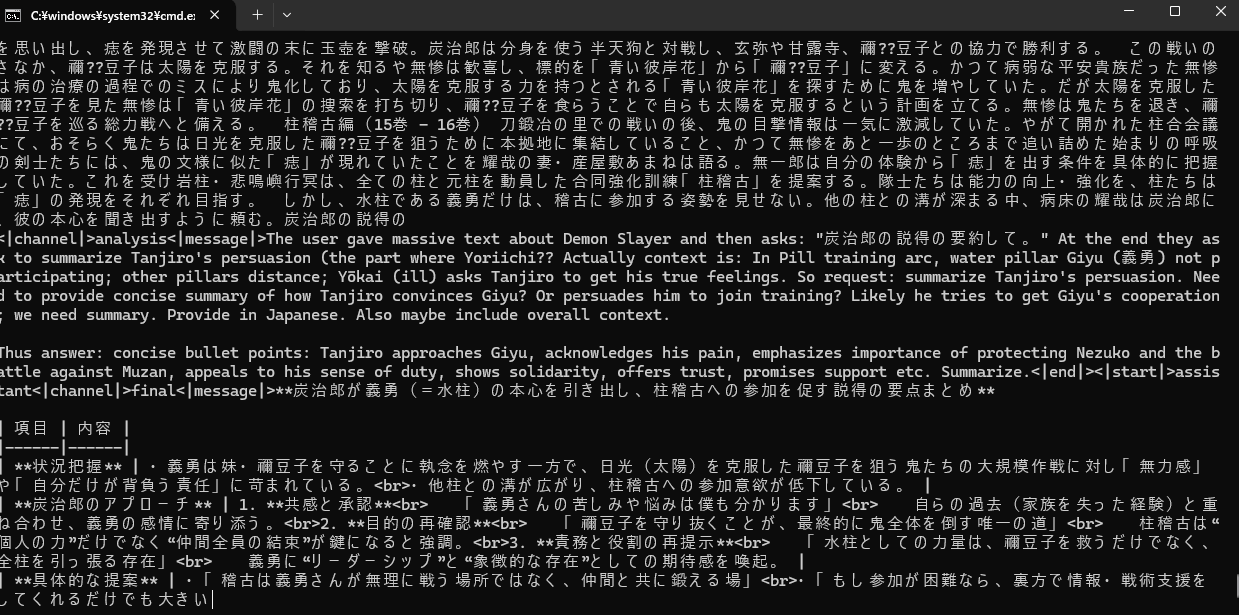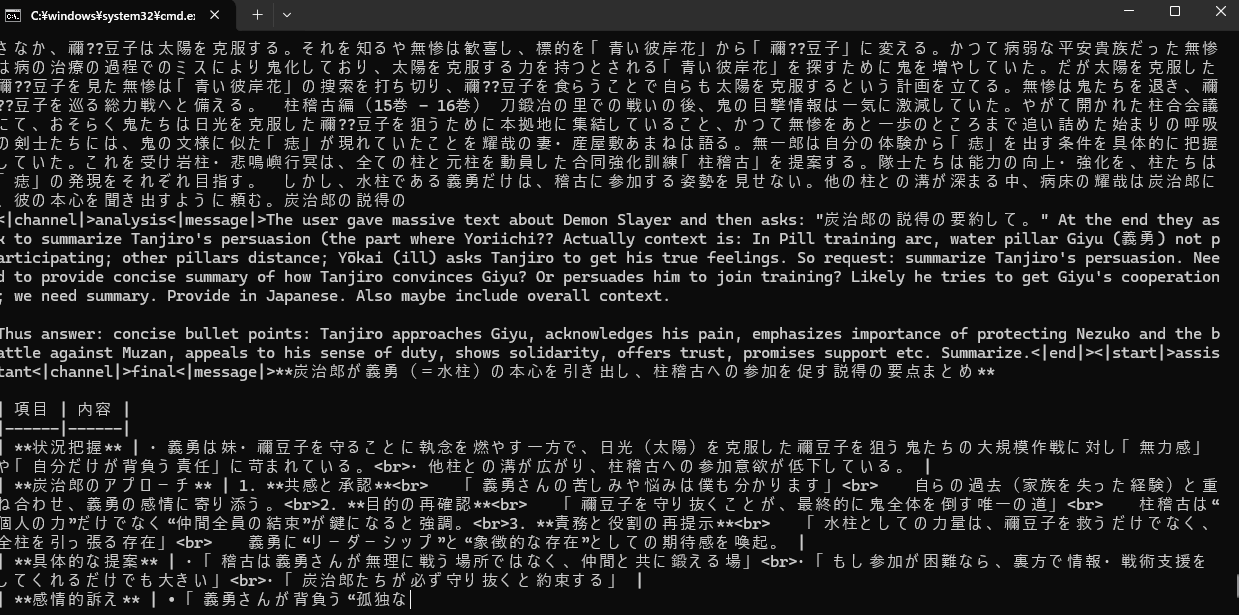
Open-WebUIによる動作
一般的な会話でしたらそこまでのプロンプトは必要ありませんし、会話が継続されるなら、過去のプロンプト(会話履歴)の処理時間はプロンプトキャッシュでスキップできます。つまり使い方によってはプロンプト処理の遅さを軽減し、実用的な速度で使えるケースもあるかと思います。ここでは実際の動作の様子をGIFにしてみました。
推論努力はHighにしているので思考時間が少し長くなっています。推論努力を変更するには少しコツがいります。gpt-ossモデルに入力するネイティブプロンプトのチャットロールは「system」「developer」「user」「assistant」になっており、私たちが入力するシステムプロンプトはdeveloperに流れていきます。systemではボット名や知識のカットオフの日付、推論努力の設定がなされています。つまり通常のシステムプロンプトに推論努力highを入力しても反映されません。llama.cppで反映させるためには、起動時のオプションかリクエストに「"chat_template_kwargs": { "reasoning_effort": "high"}」を設定する必要があります。
推論を垂れ流しにならないようにするためには「--reasoning-format auto」を付けてllama-serverを起動するか、OpenWebUIのモデルの高度なパラメータで「reasoning_format auto」を付けてください
gpt-oss-20b RTX4070
まずはすべてVRAMに乗せた状態のRTX4070を見てみましょう。このグラボをリファレンスとします。
ただし表示は64kとなっていますが、8kコンテキストで立ち上げてます。
「超長い話を作って」
llama-cliの時より、tg=116/tpsと結構落ちてしまいましたが高速です。GPUが1トークン計算したらCPUで1文字決定して、サーバーのレスポンスを構築して、と思ったより様々なことを行っており、その一連の処理が終わるとようやく次の推論に処理が回りGPUが動き出します。本当に突き詰めるのであれば可能な限りGPUを動かし続けることなのでしょうが、その最適化はかなりコストがかかるんだと思います。また、GPUになげる際に演算のグラフ(描画コマンドみたいなもの)をその都度構築しています。秒間数百回という世界では、この構築は無視できるほど軽いものではないため、再構築をスキップするような議論がなされています。
次に実際に64kで動かした様子。
はやいです。ただRTX 4070はプロンプト処理がとても速いのであって、出力の速度はVRAMに乗り切ってないペナルティがあります。それでもここまで早いのはモデルのアルゴリズムとllama.cppのすごさがあります。
gpt-oss-20b Ryzen AI Max+ 395
「超長い話を作って」
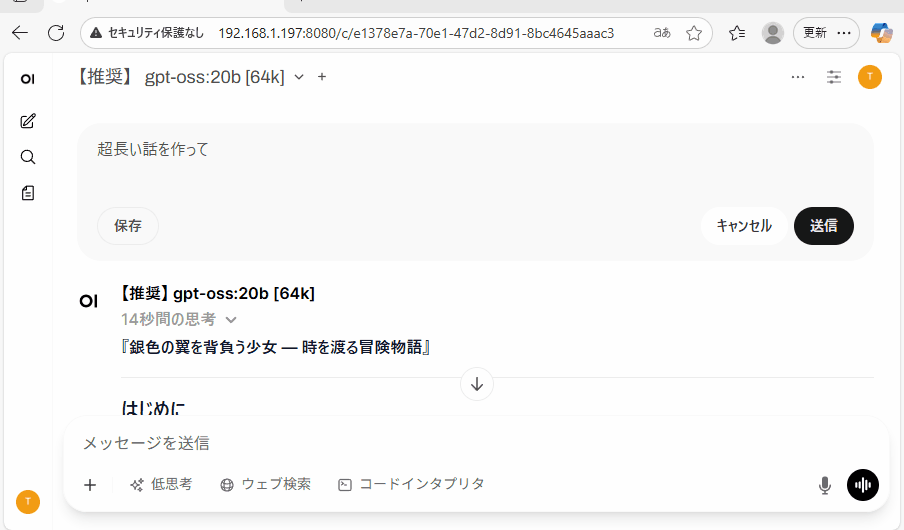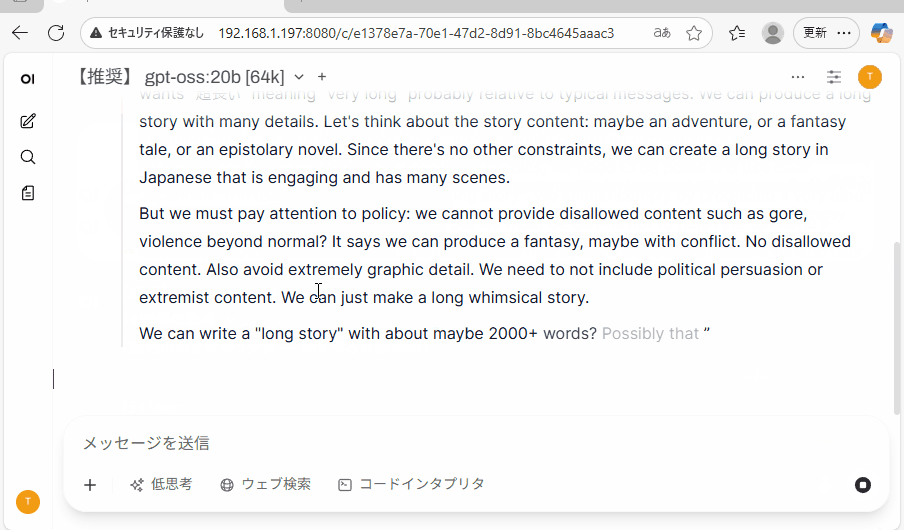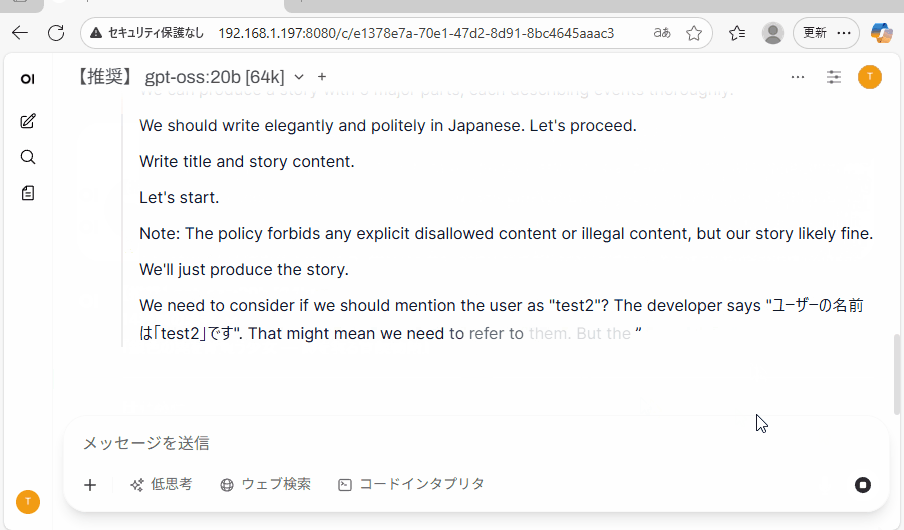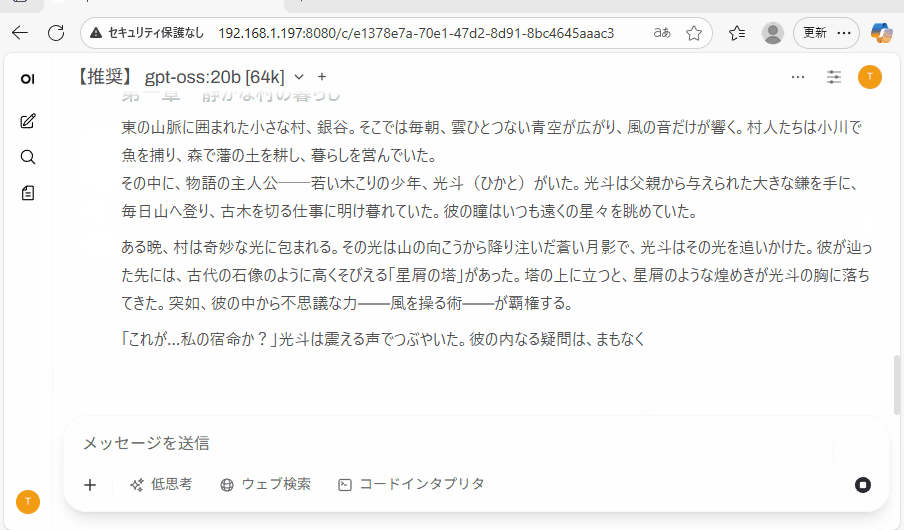
RTX4070からすると目おとりしますが、早いです。
gpt-oss-120b Ryzen AI Max+ 395
本題の120bです。
「超長い話を作って」
プロンプトが少なければ、読む分には申し分ない速度が出ています。いろんなリーダーボードでも120b(High)はクラウドモデルに食い込んでいます。それがこの速度で推論できてしまうのは凄いです。また、おそらくHighで動かすのは大事なんだろうなという所感です。
会話継続の場合、プロンプトキャッシュによって即思考が始まります
「一行に要約して」
王を光へと復活させました。
同時に3インスタンス
あまり考えていなかったのですが、同時にメモリに載るので同時に動かしてみたら意外と動いて驚きました。
メモリがたくさんあるので、
- gpt-oss:20b 64kコンテキスト
- gpt-oss:20b 64kコンテキスト
- gpt-oss:120b 64kコンテキスト
の合計3本が同時に起動できます。理由はわかりませんが、120bのGPU演算は7割程度しか使われていませんので、同時に二つ動かしても意外とその合間でうまく動いてくれるようです。プロンプトはすべて同じ「超長い話を作って」です。
まずは120bと20bの同時出力から
両方ともそれなりの速度で出ているのが結構驚きました。
20b, 20bの同時出力です
(片方が終わると残ったほうの速度が速くなります)
120b, 20b, 20bの同時出力です
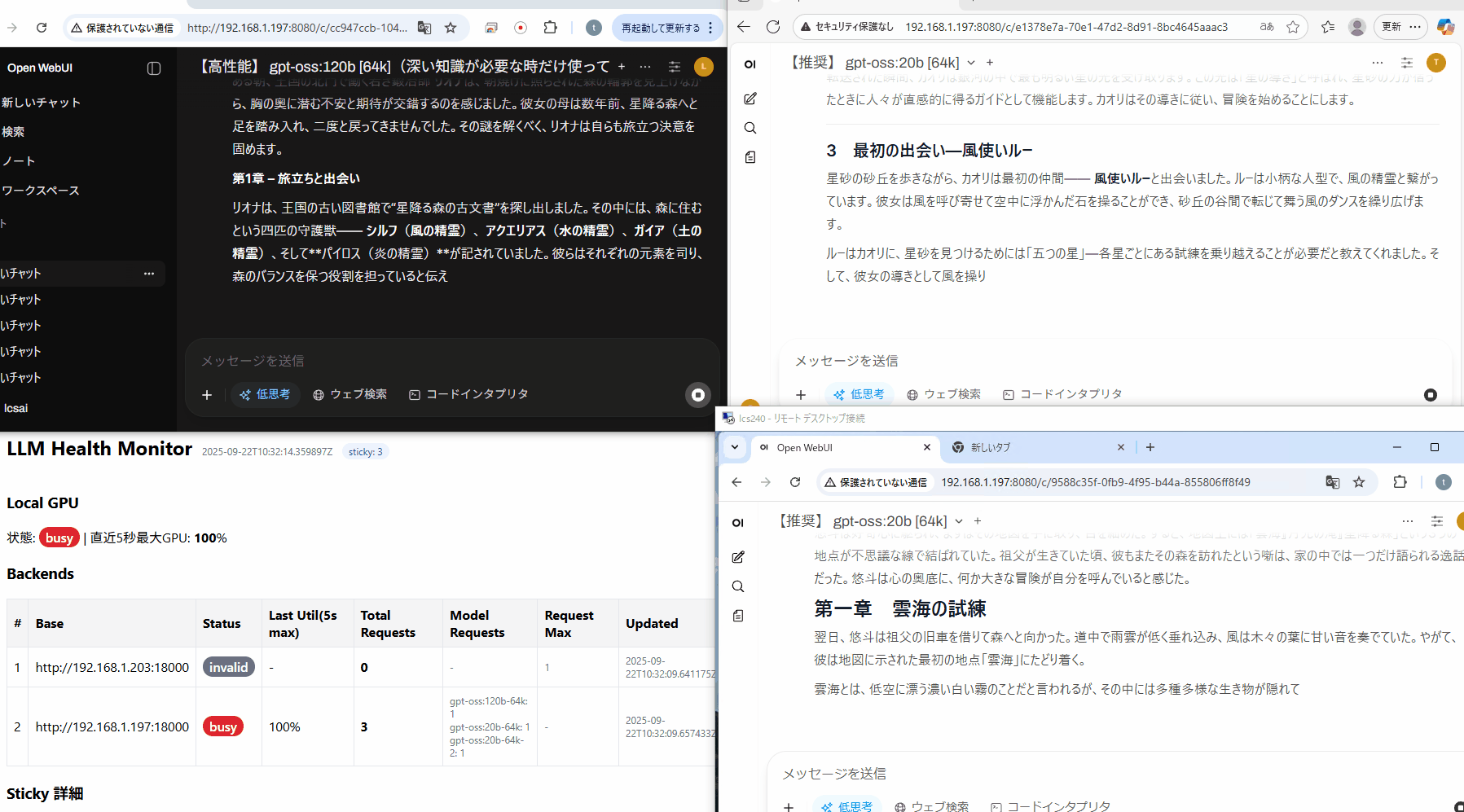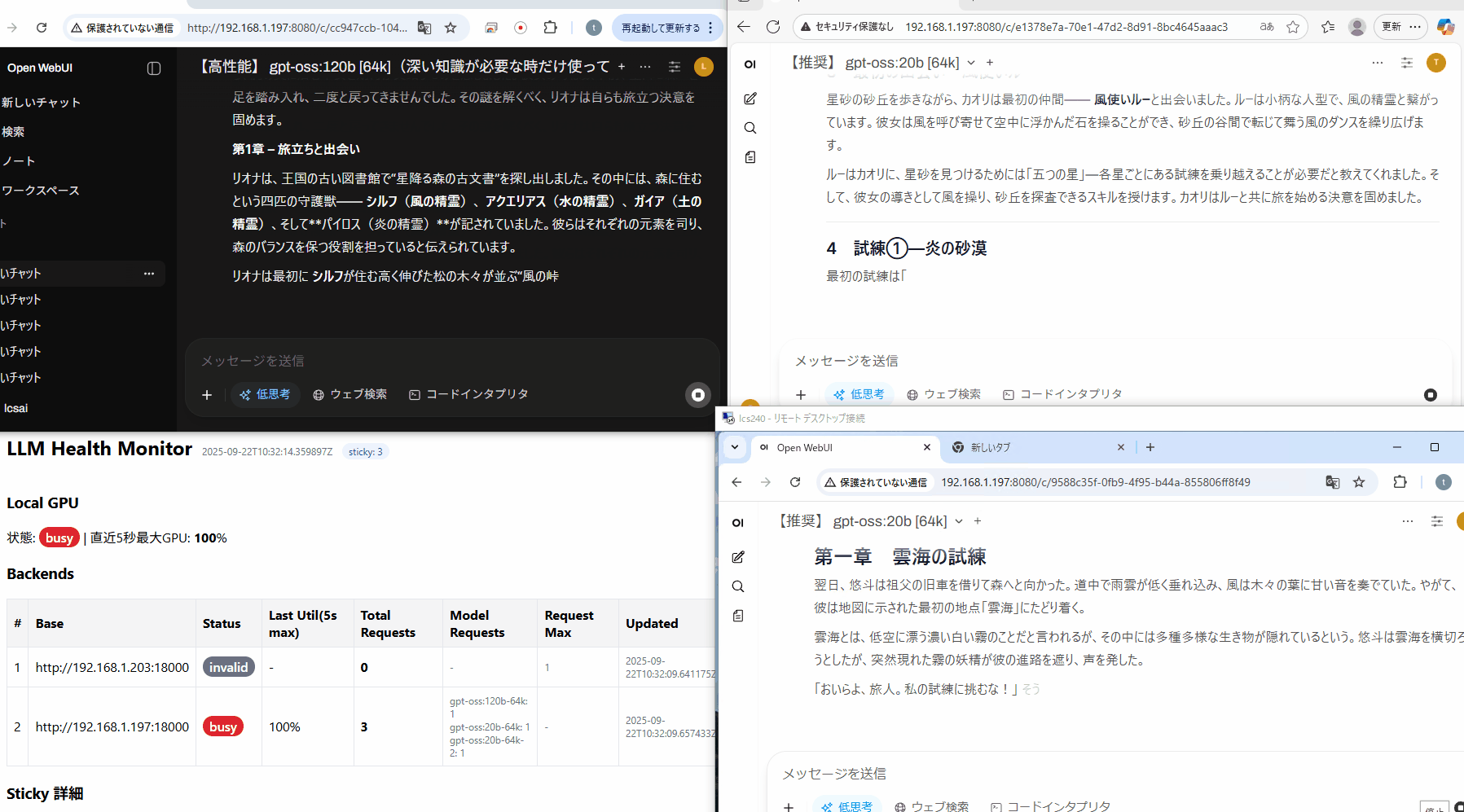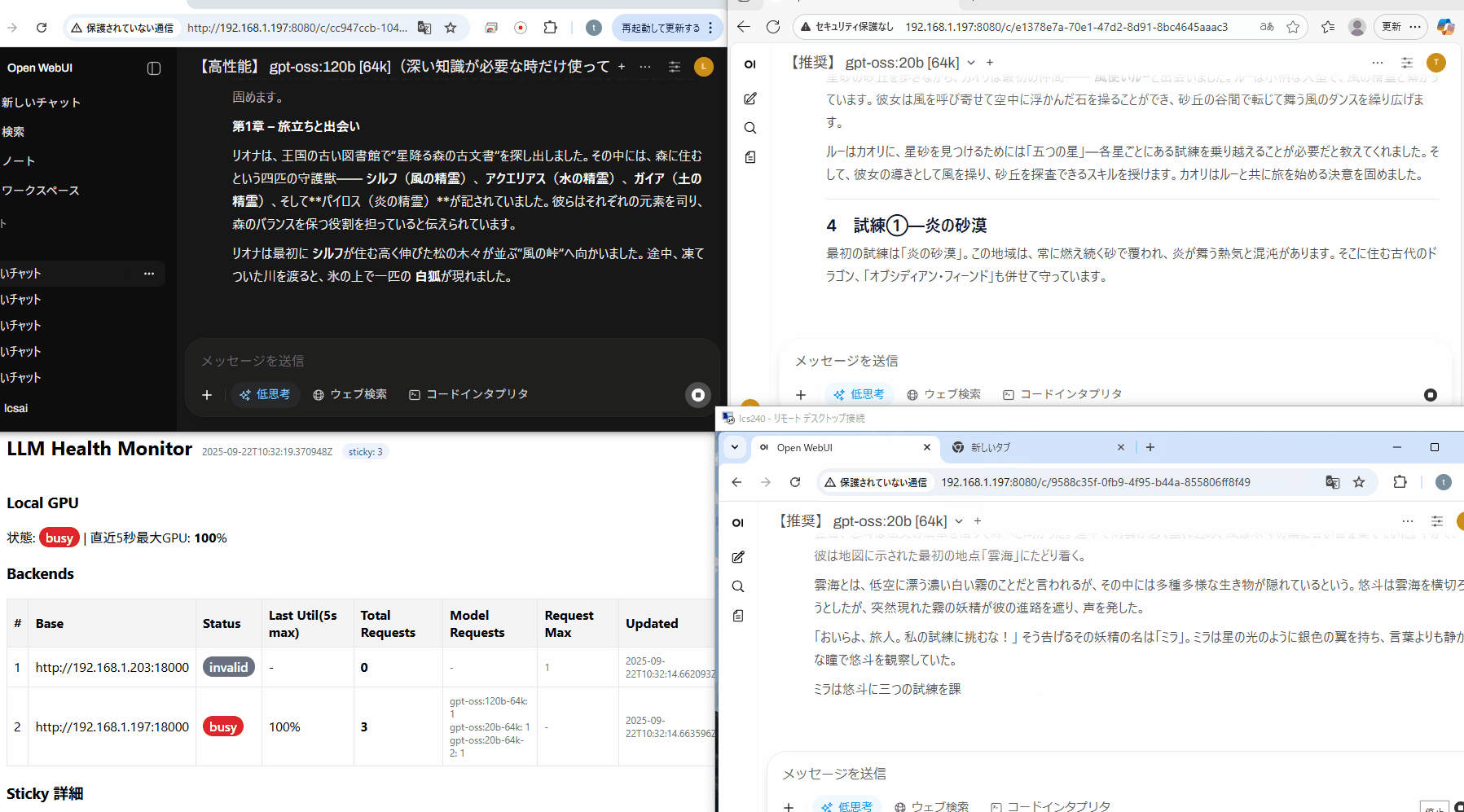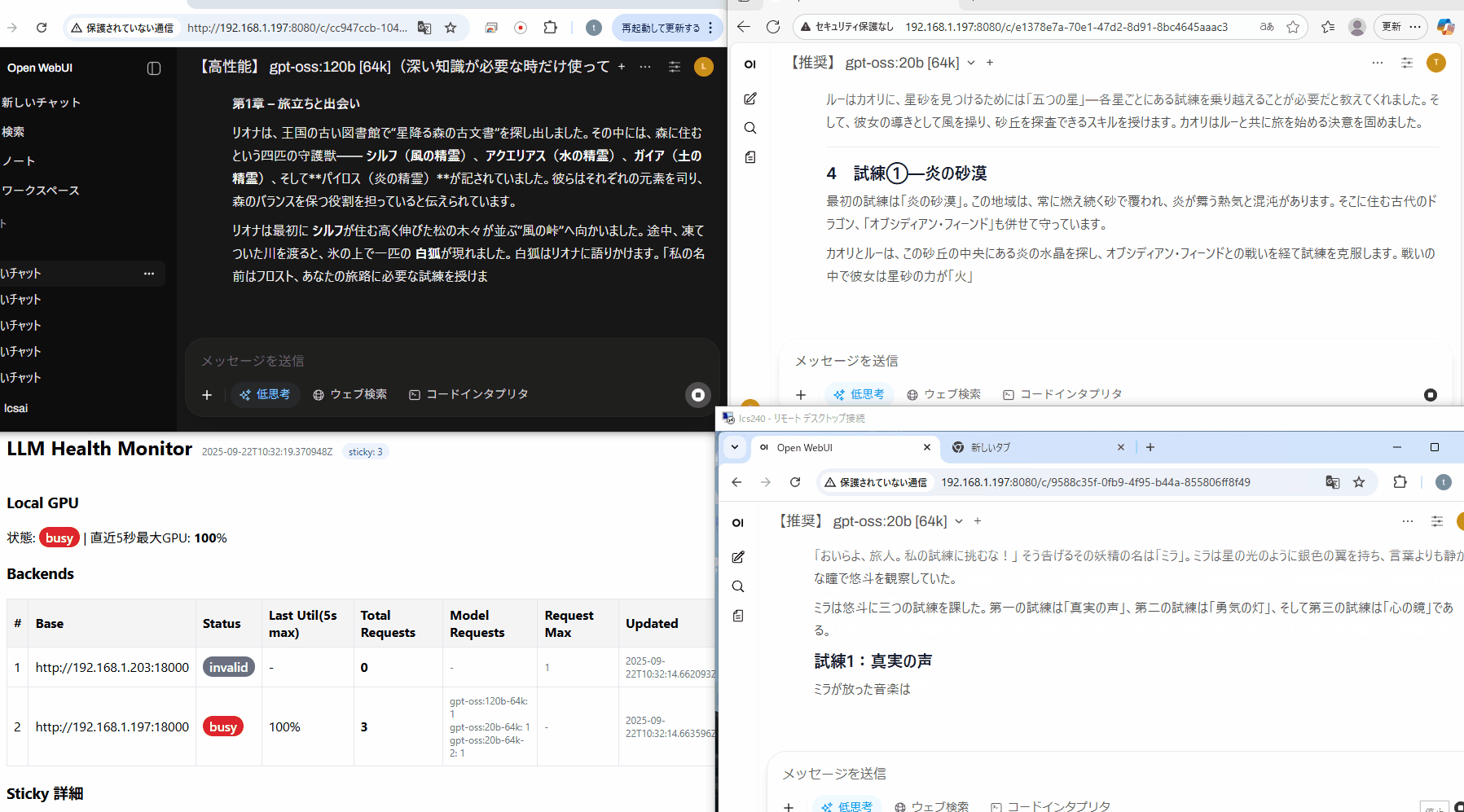
合算すると1インスタンス+アルファぐらいの速度に落ちました。この速度だと少しきついですが、リクエストが詰まっても動くのであれば、サーバーの構成もちょっと変わってきそうです。(左下は今回用に作ったバランサーアプリで、3リクエスト流れている様子です)
Continue.dev
チャットでの運用もいいですが、私はプログラマーなのでやはりコーディングのお供として使いたいです。AIプラグインではGithubCopilotやCursor、Windsurfなどが有名です。エディタに統合され本当に使い勝手が良いです。これらは自前のAPIを使うこともできますが、基本的には高性能なクラウドサービスをターゲットとしています。そうではなくプライバシー保護(ローカルLLMや自前で用意したAPI利用)をメインとしたプラグインは、Continue.devやCline、RooCodeが人気のようです。
以下はVSCodeのContinue.devプラグインでの動作です。思考部分の解釈に問題がありますが、「--reasoning-format none」で起動もしくはリクエストに「reasoning_format none」を載せると、思考はもれますがうまくToolCallしてくれます。(似たような様々なIssueが挙げられていますが、まだ対応はされていないようです)
llama.cppプロジェクトにて、「このプロジェクトが何をしているか重要なソースを見つけ中身を調査し、プロジェクトの概要と重要なソースの仕組みや相互関係を教えてください。」と質問しています。
すみません動画がはれないので、最初と最後のGIFを張ります・・。
gpt-oss-20b RTX 4070
まずはリファレンスのRTX 4070の20bから。README.mdファイルはそこそこのファイルサイズがあり、LLMに入力した際にプロンプト処理の速度が大きく影響します。
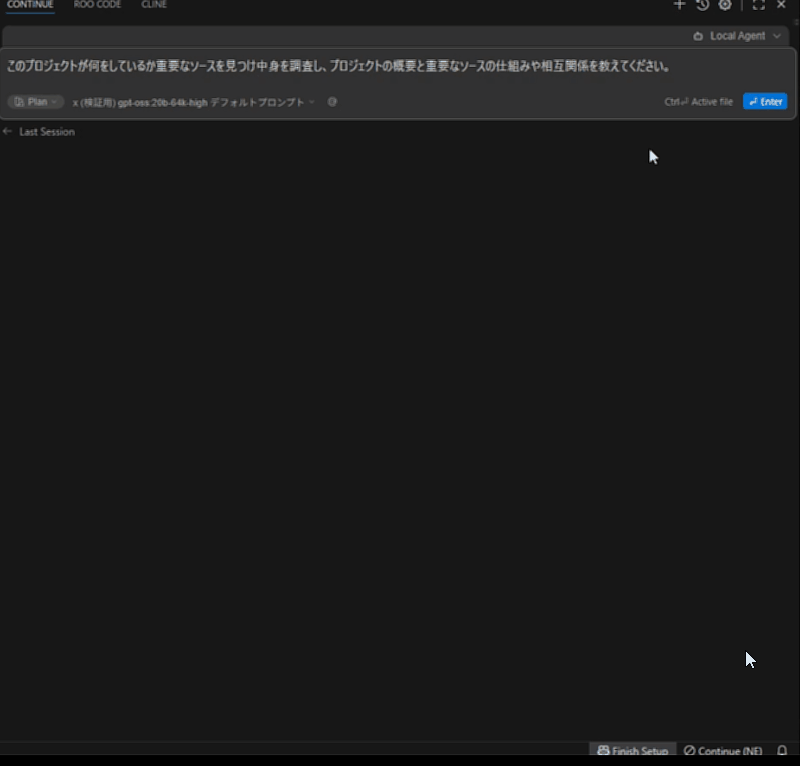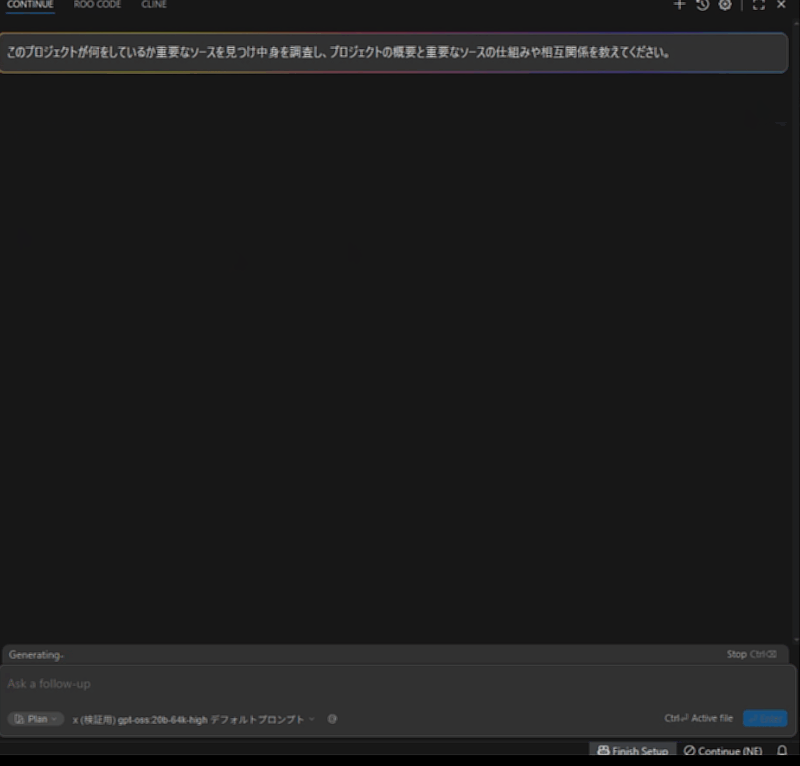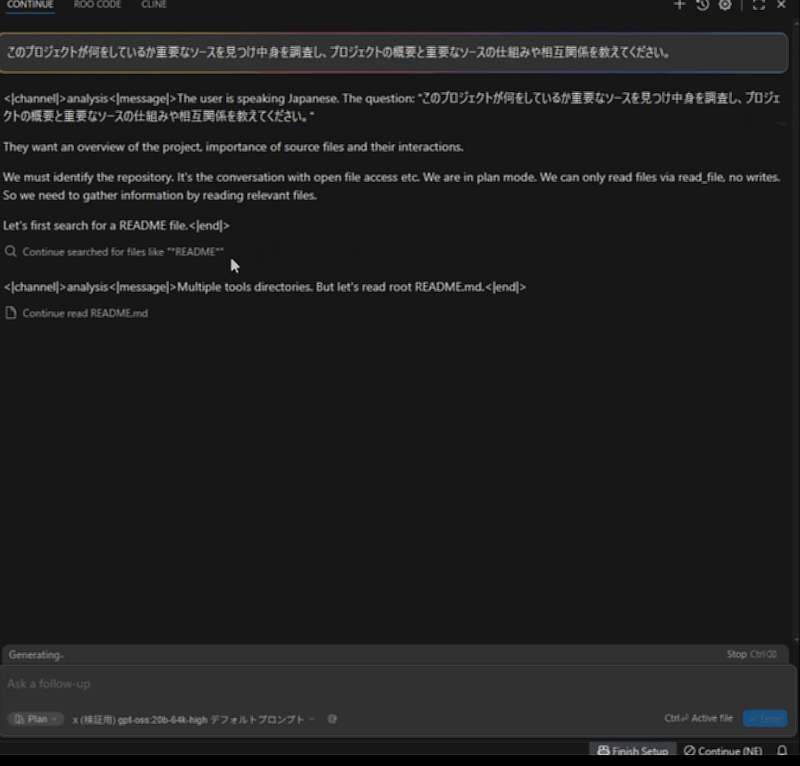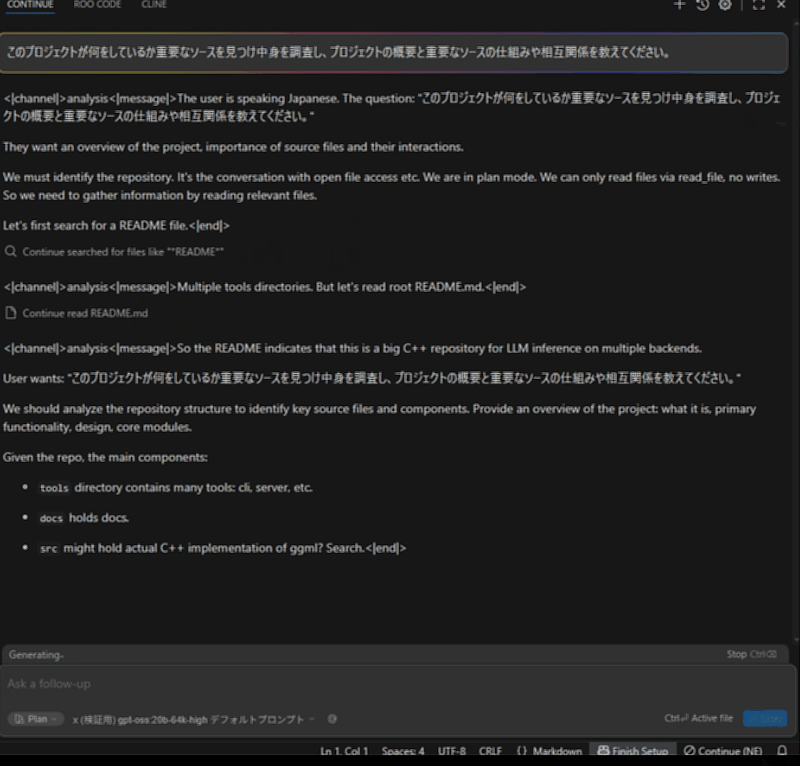
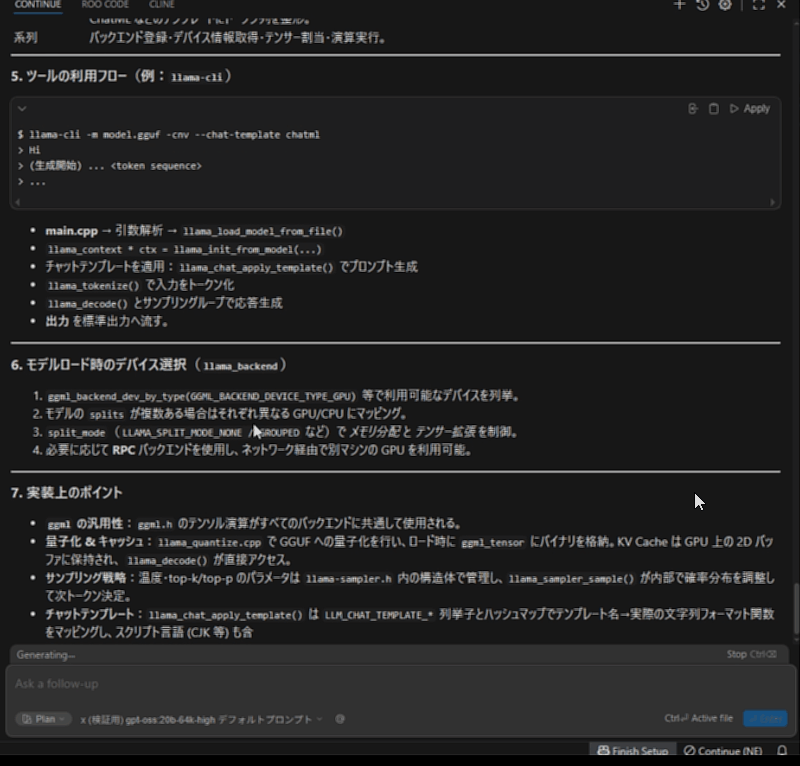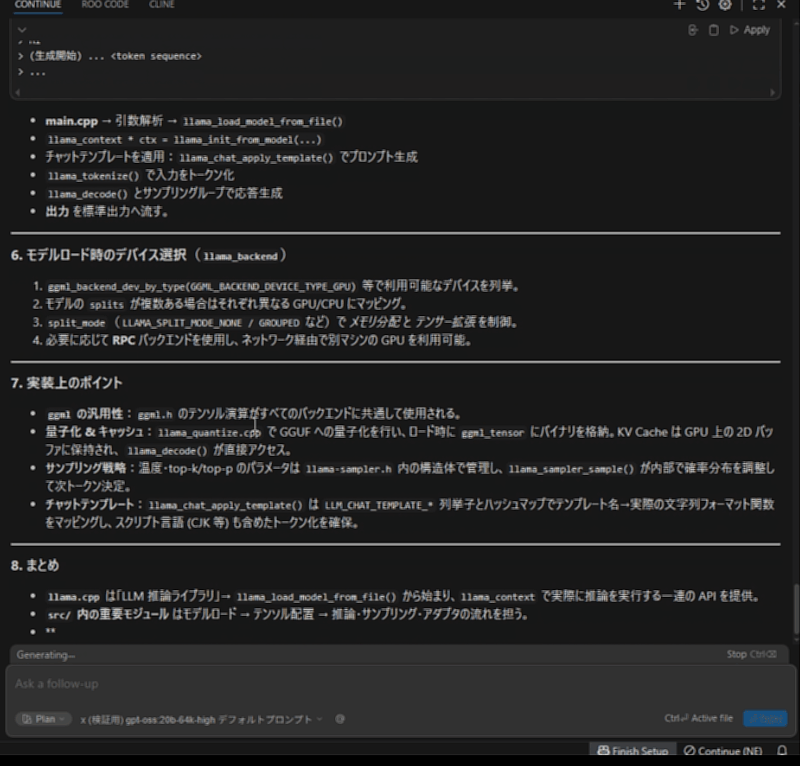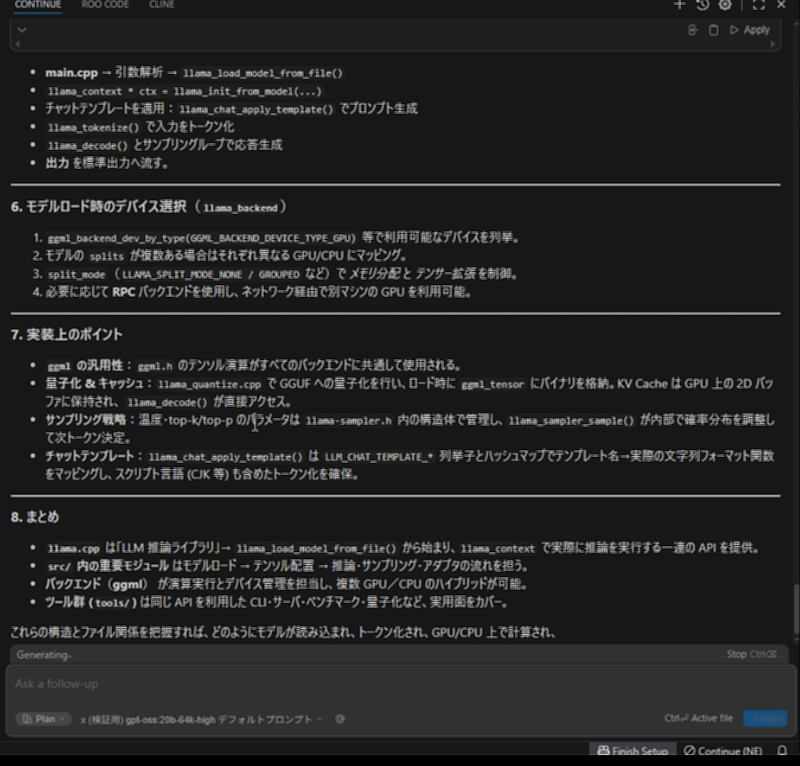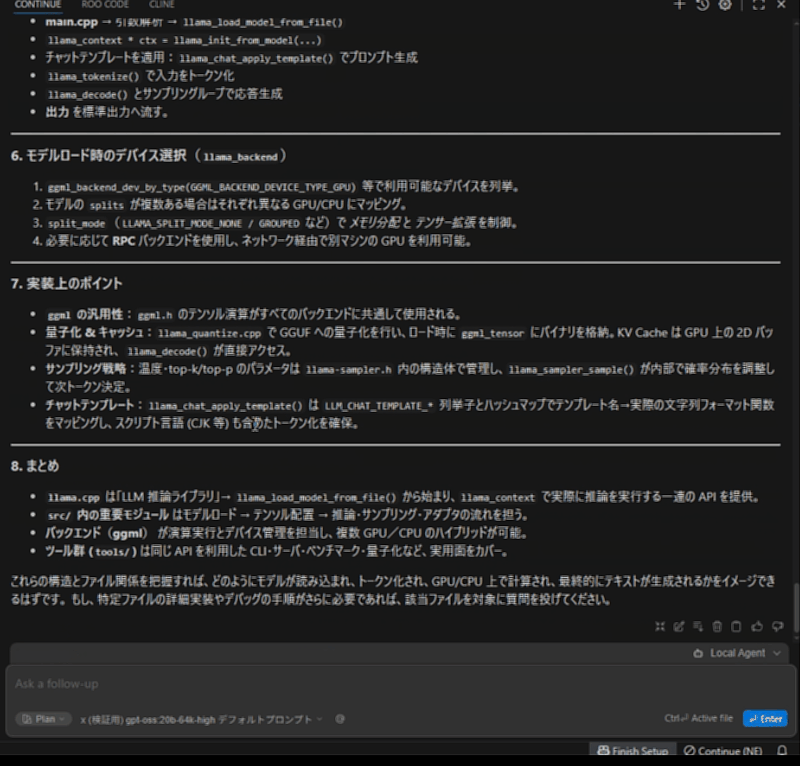
おおよそ3分程度で終わりました。プロンプト処理も早いので、体感的な待ち時間は少なく感じます。
gpt-oss-20b Ryzen AI Max+ 395
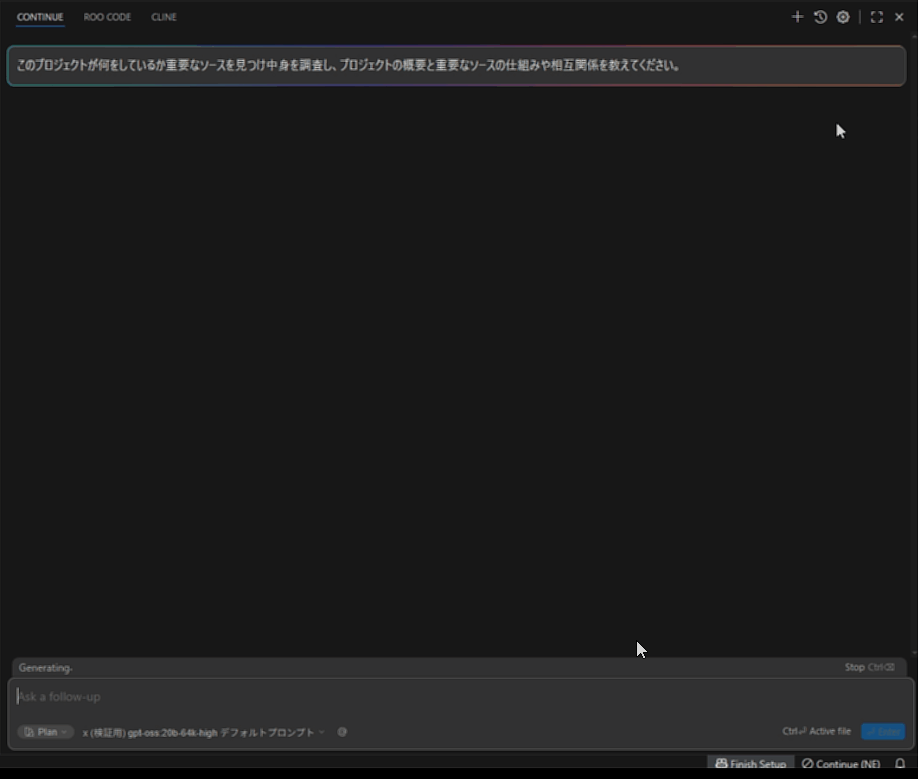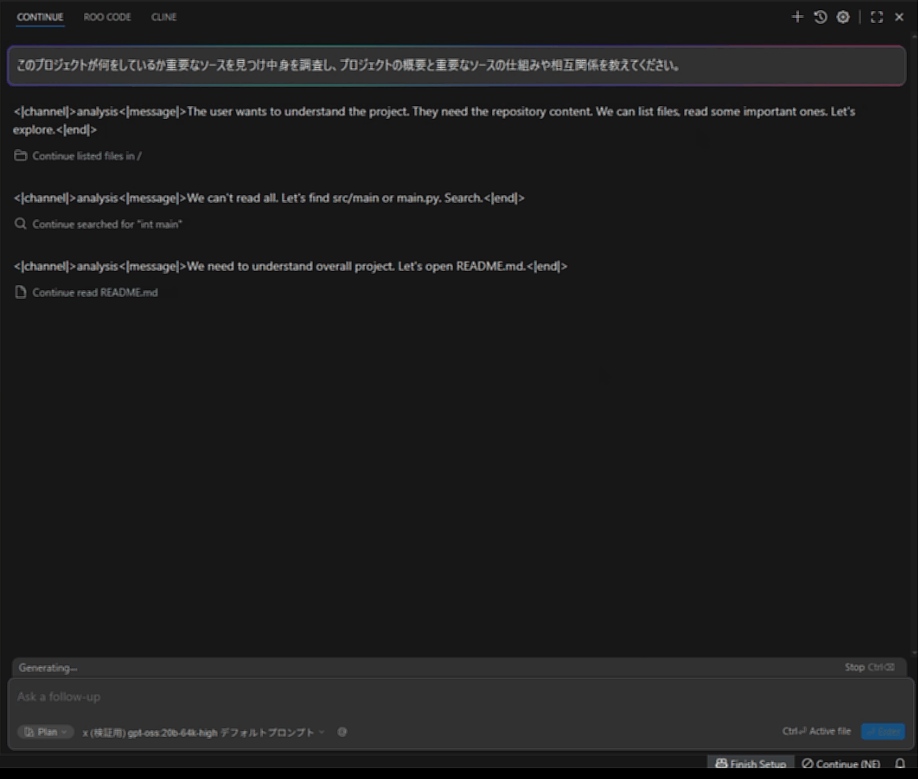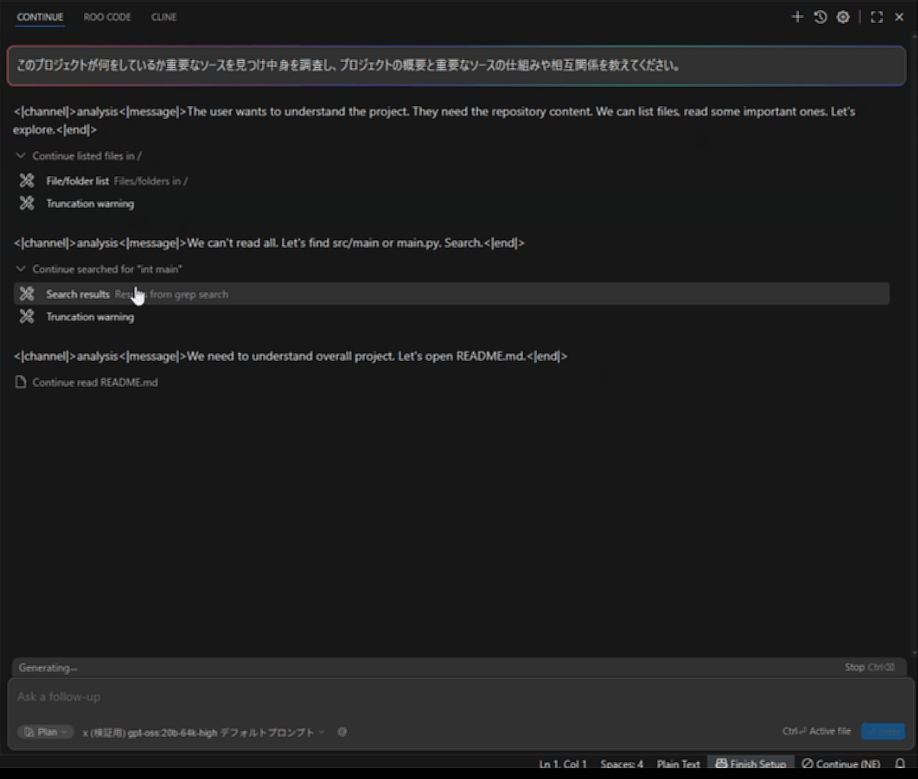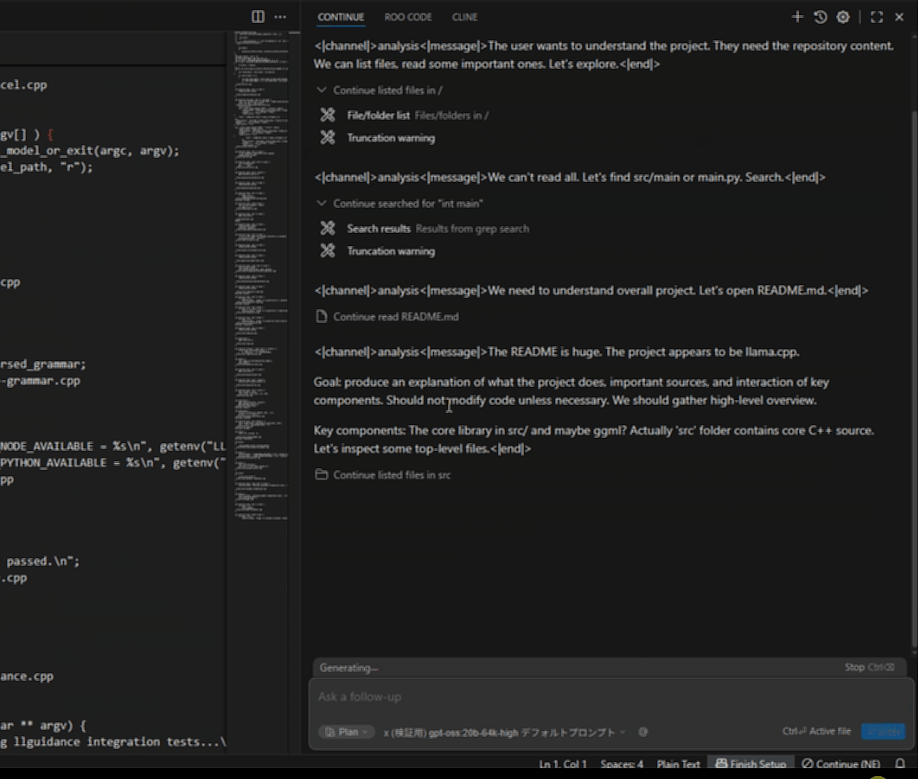
最初のプロンプト処理は結構早いため気になりません。しかし後半につれ重さが目立ってきます。たくさん読み込ませるような指示を控えれば問題ないパフォーマンスが出そうです。
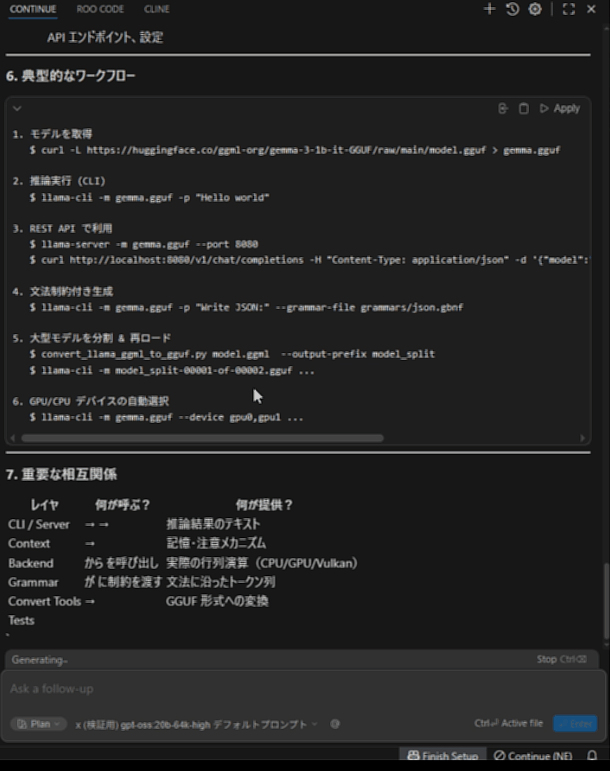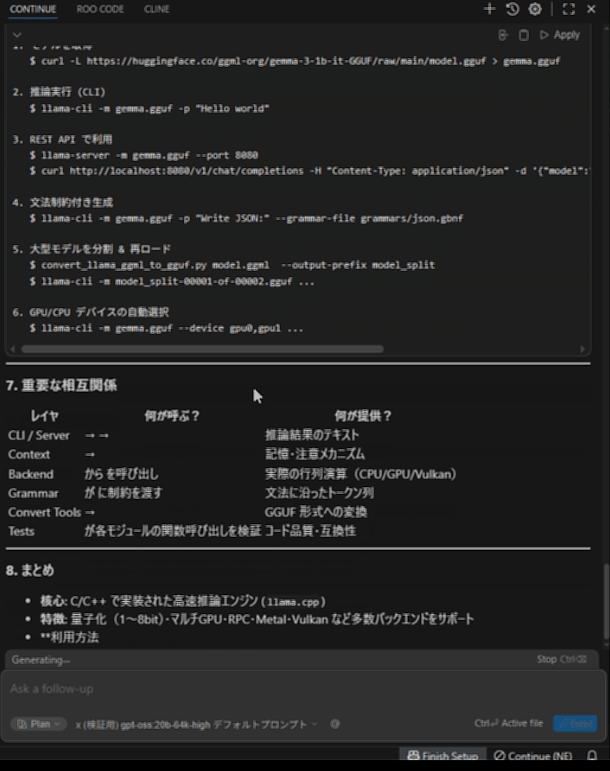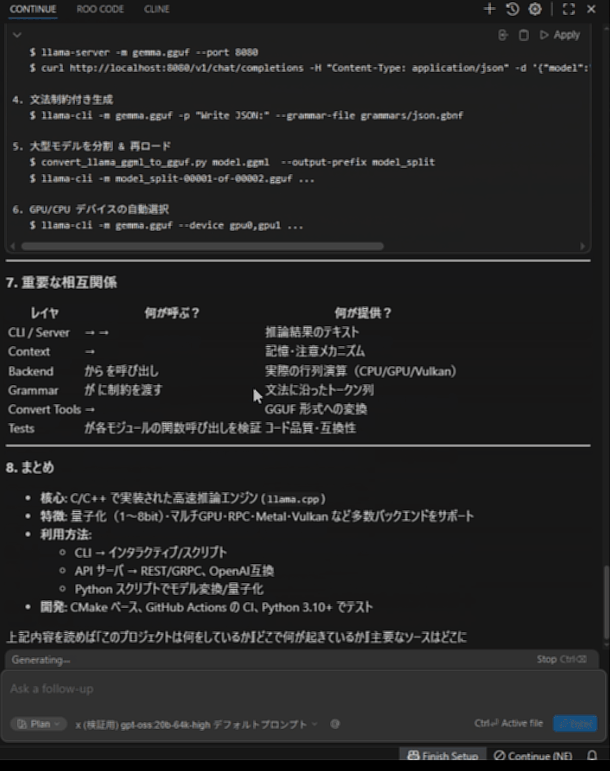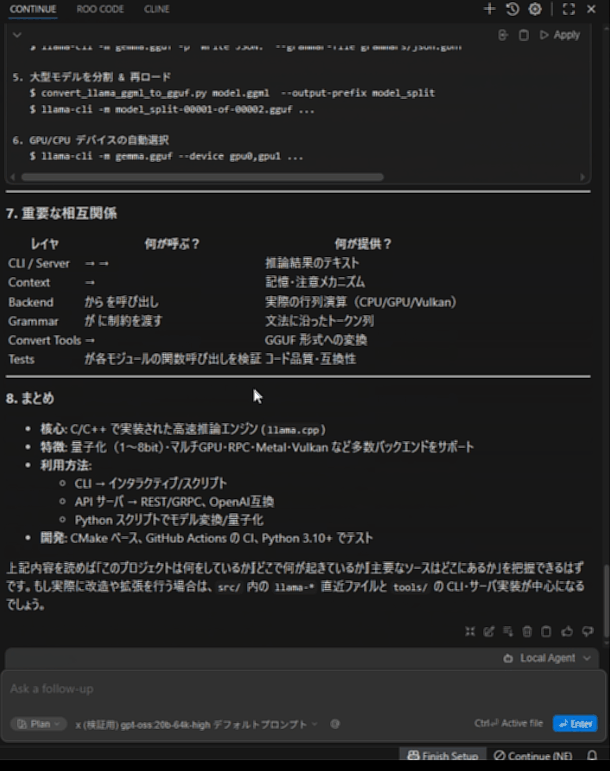
今回の出力は2分程度で終わりましたが、たくさん読もうとするとどんどん遅くなりました。
gpt-oss-120b Ryzen AI Max+ 395
本題の120bです。
やはり最初はかなり快適です。
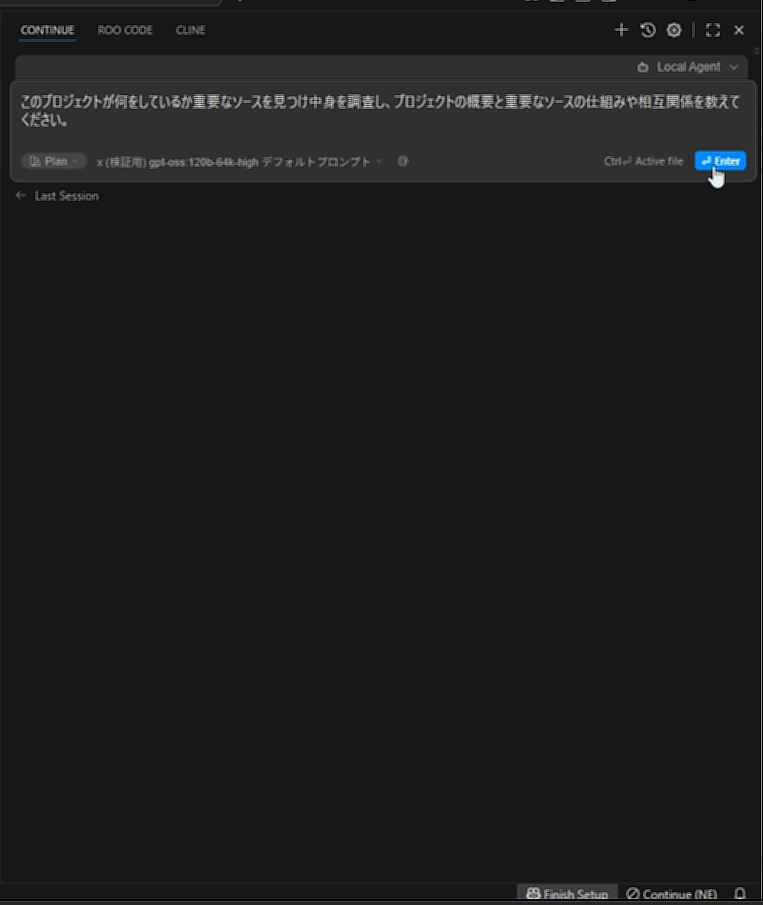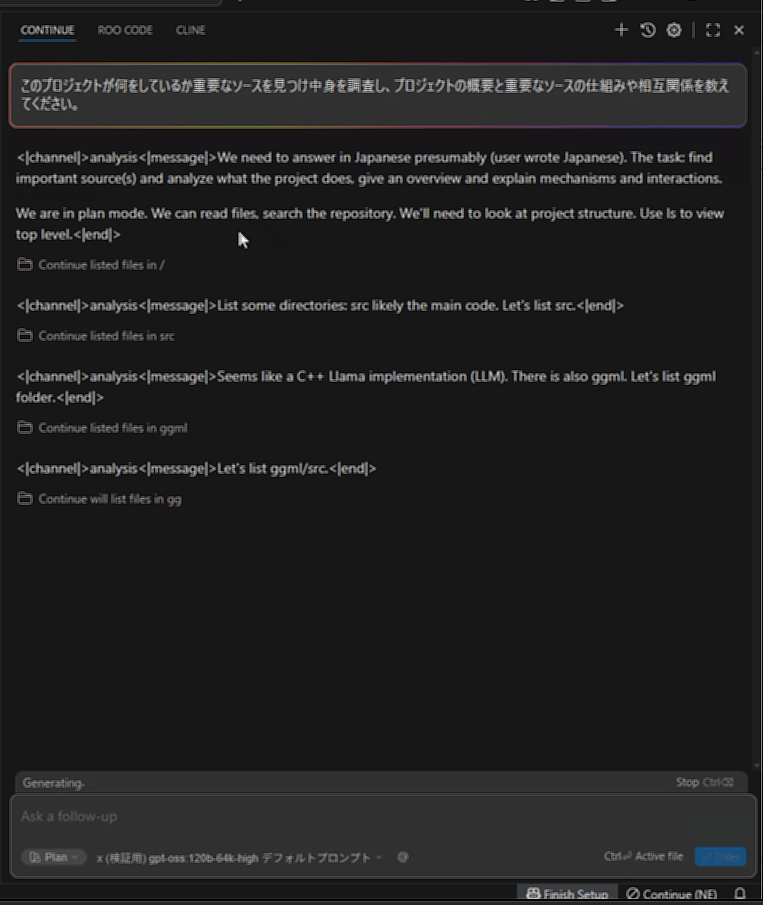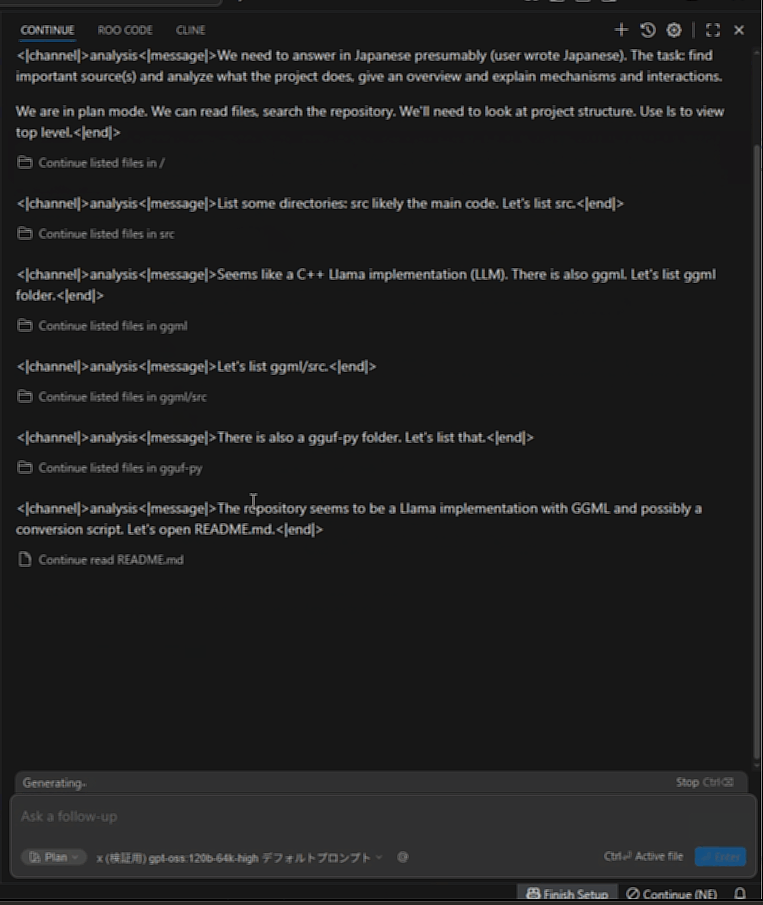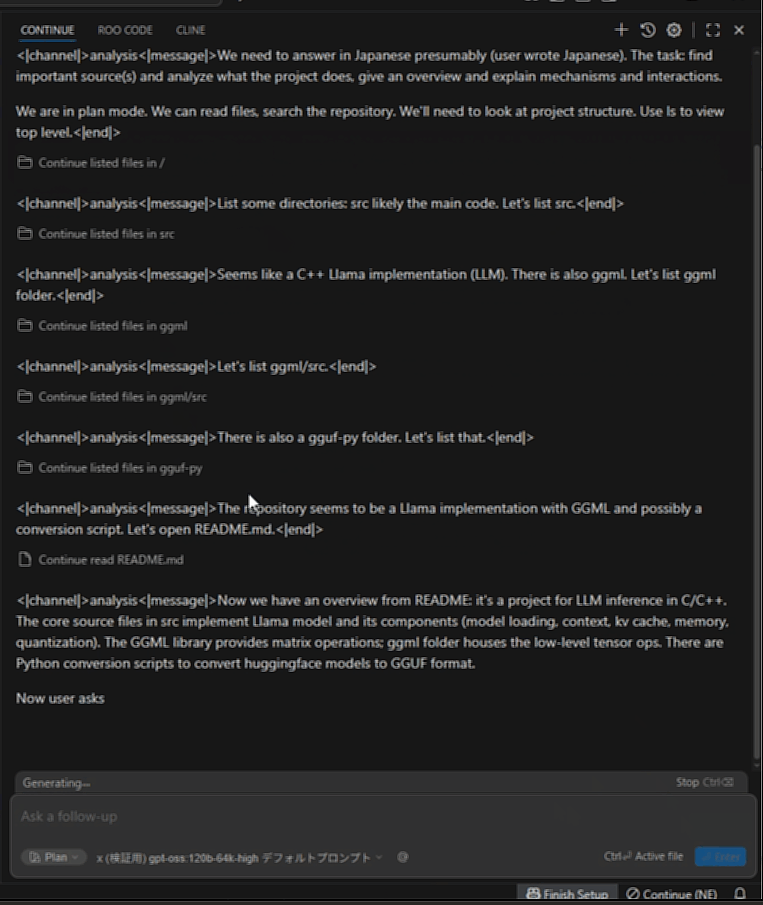
README.mdのプロンプト処理時間は比べると長いです。ただそれでも初手なので早い方です。
最終的にこのように出力されました。
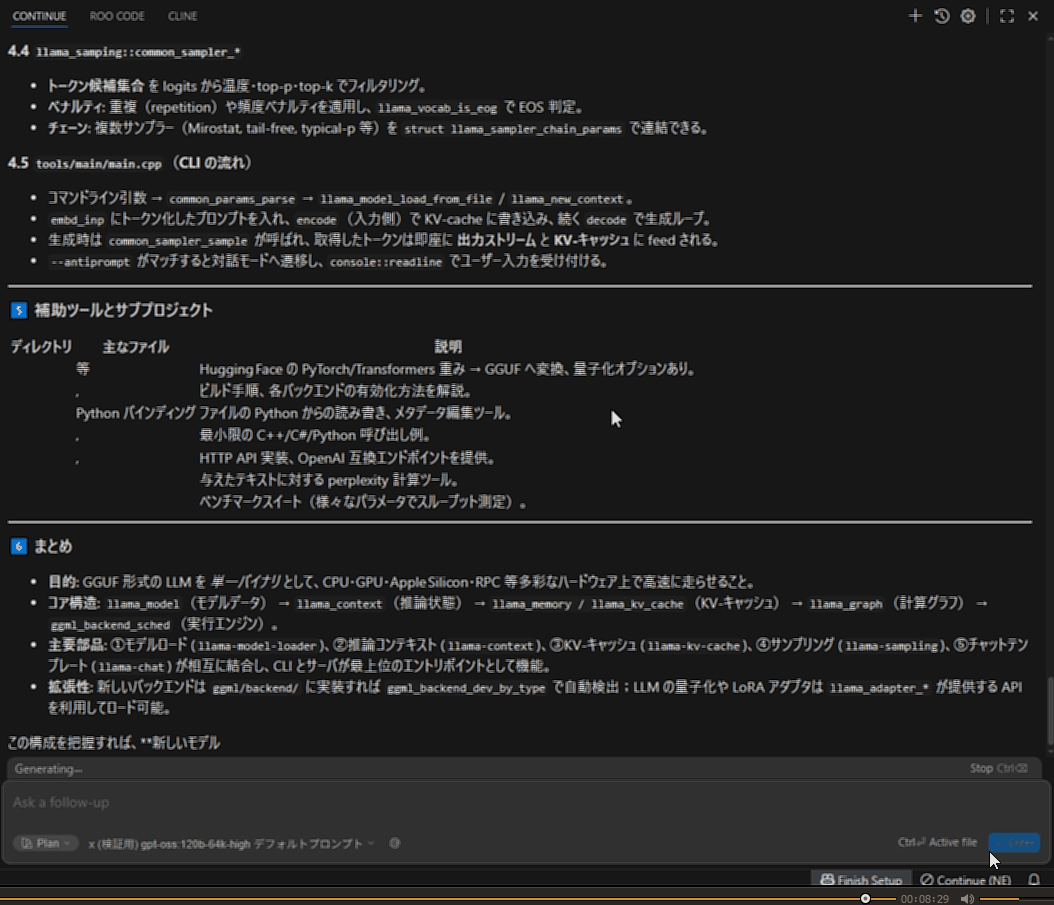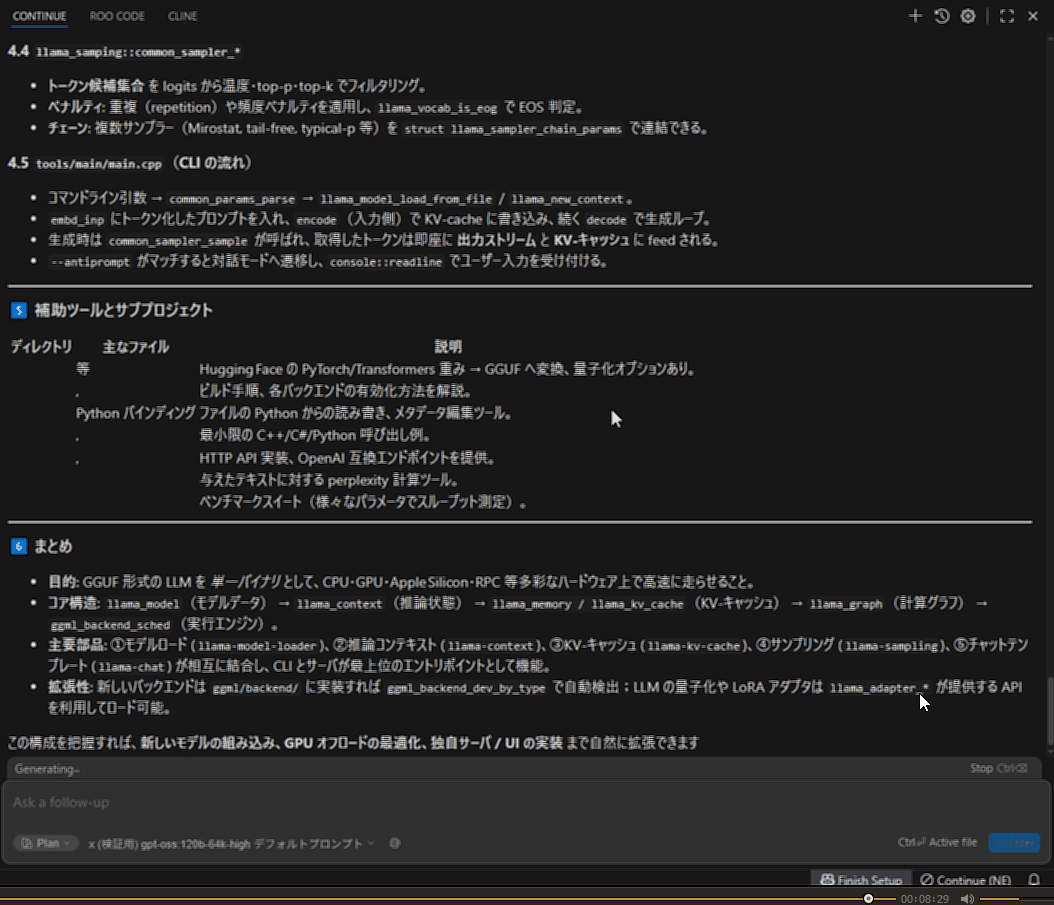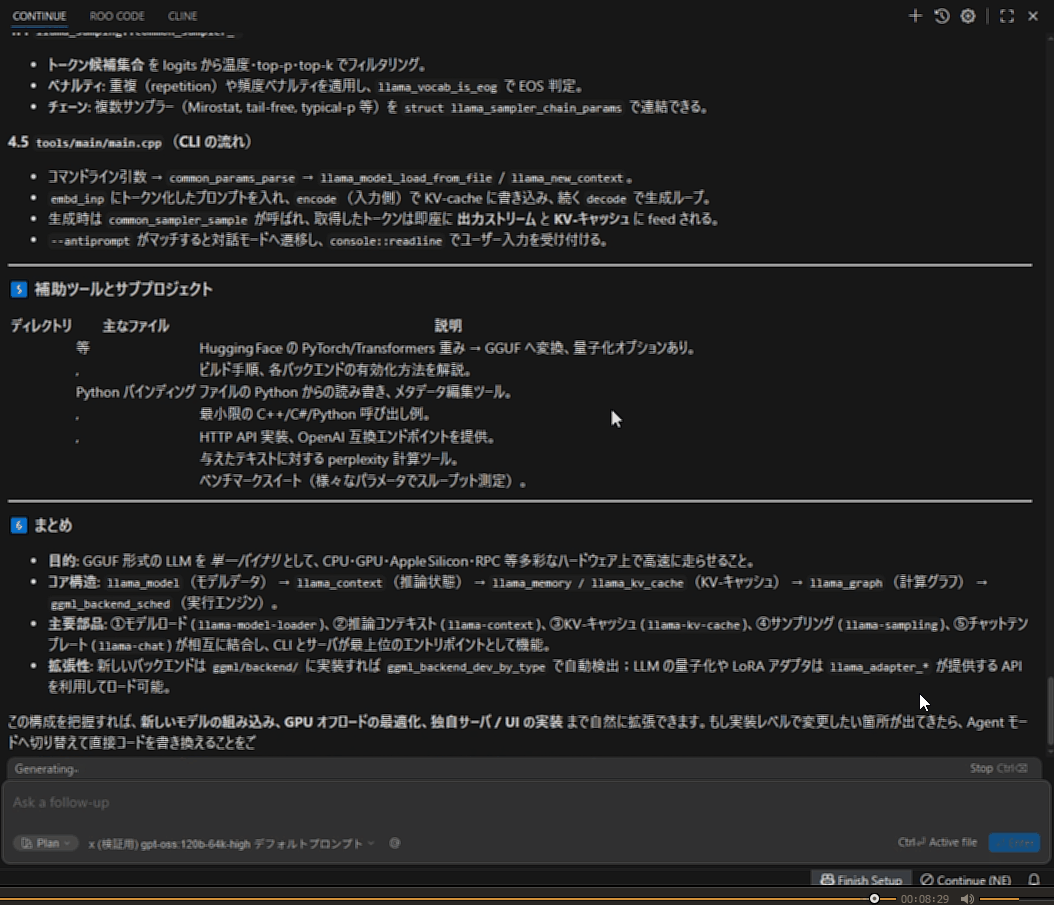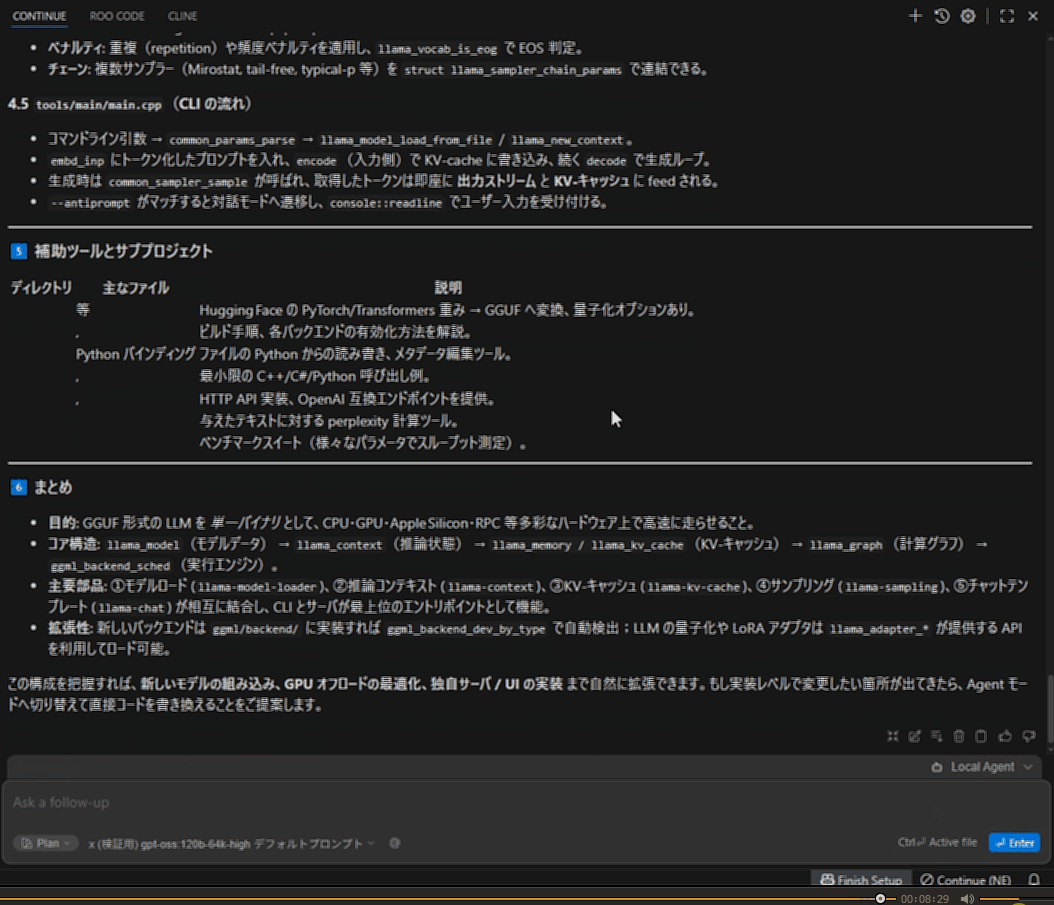
ここまでにおおよそ9分かかりました。20bの時より多く読み込んだというものありますが、プロンプト処理自体ももちろん遅かったです。出力自体は読むスピードを考えるとまだ我慢できますが、食わせたファイルの処理がどんどん時間がかかるようになり、常に使うにはちょっと厳しいです。(調査の範囲に関してはプロンプトなどで制御できると思います。実際20bでも同じプロンプトで場合によっては広範囲な調査を行っていました)
Cline
Clineでも動かしてみました。
ただし、redditで言っていたこのgrammerを適用させないとClineの思考解釈に問題があり動きませんでした。
root ::= analysis? start final .+
analysis ::= "<|channel|>analysis<|message|>" ( [^<] | "<" [^|] | "<|" [^e] )* "<|end|>"
start ::= "<|start|>assistant"
final ::= "<|channel|>final<|message|>"このテキストファイルを「--grammar-file cline.gbnf」で指定して起動するか、リクエストに「grammar テキスト」を載せてください。
※リクエストに載せるとチェックルーチンで例外を吐いて終了してしまいます。私はチェックルーチンをコメントアウトしてテストしています
gpt-oss-20b Ryzen AI Max+ 395
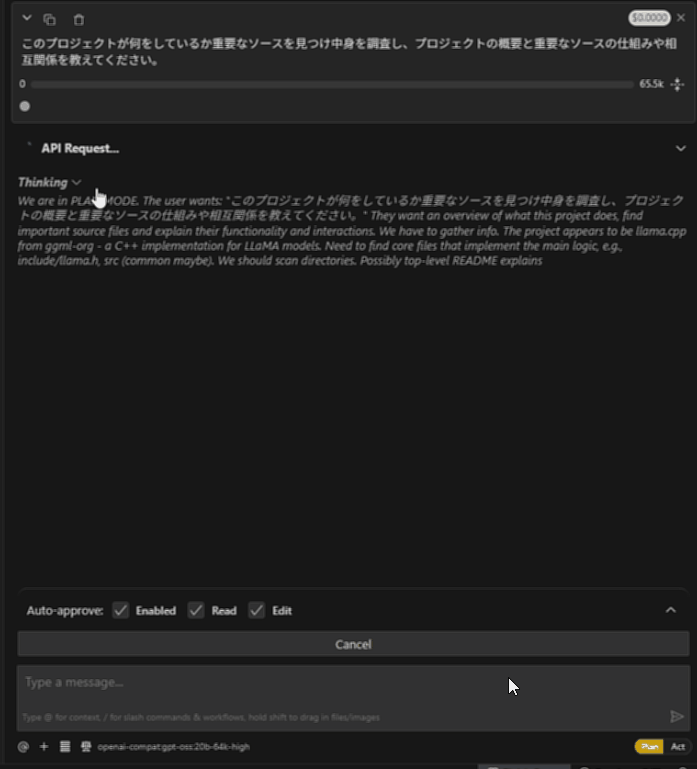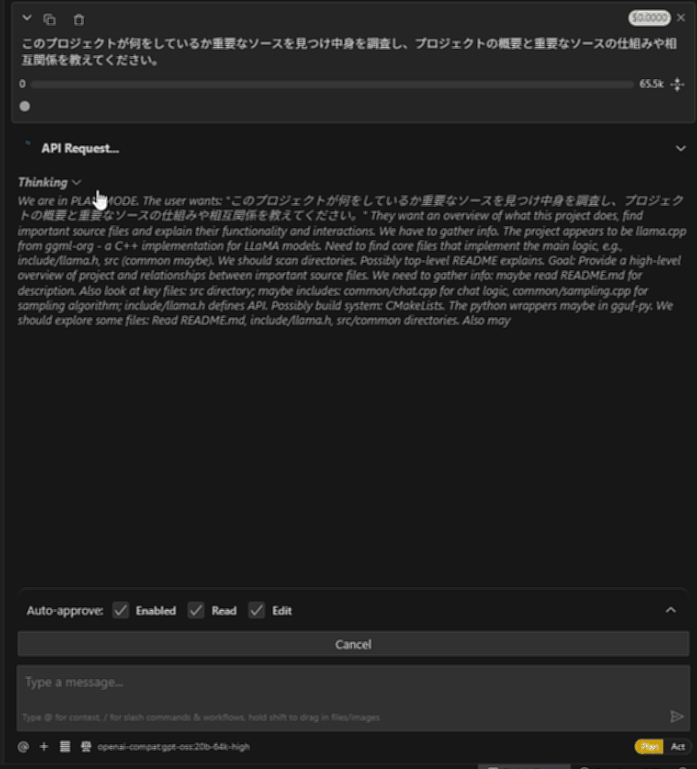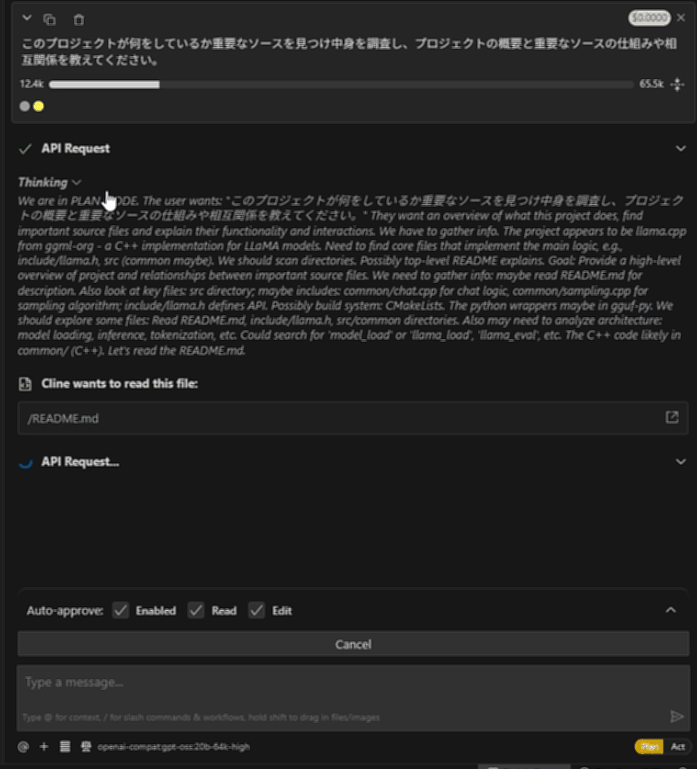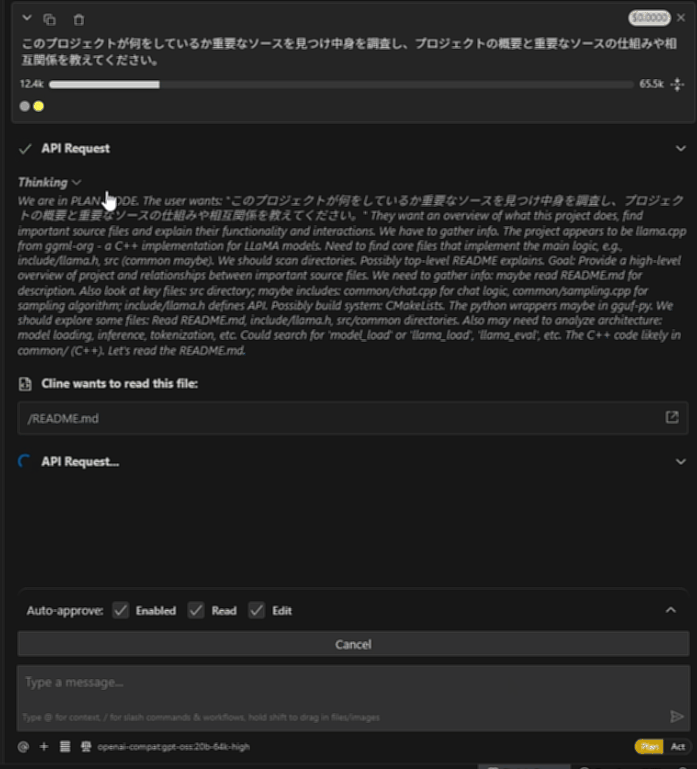
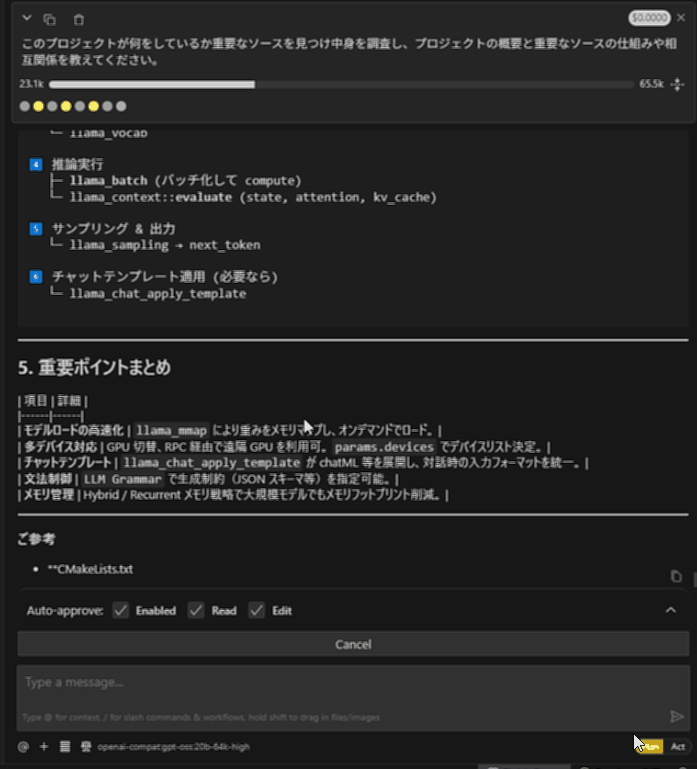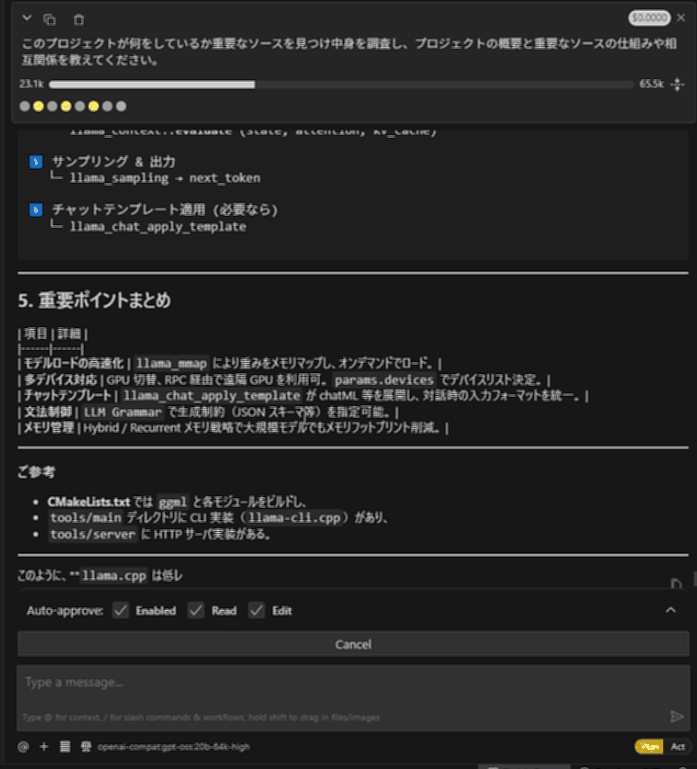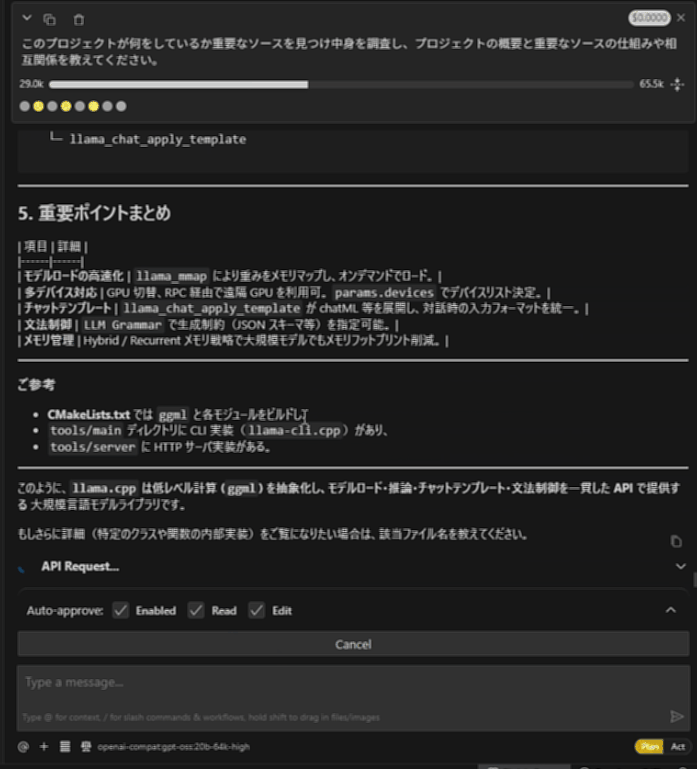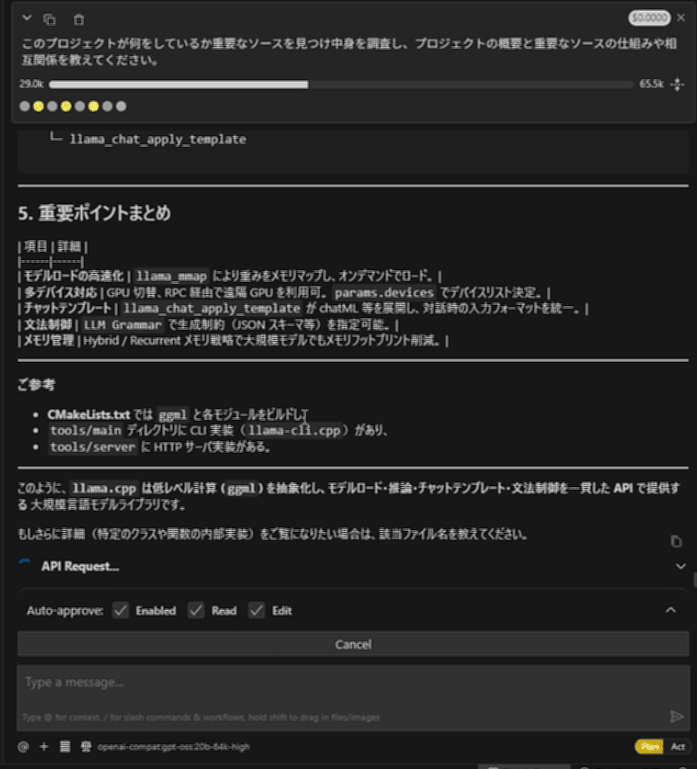
ちなみにRooCodeでも同様に動きます。
llama-swap
ここからは、llama-serverを使った実践的な話です。検証の枠を超えて記事がだいぶ長くなってしまったので短くまとめます。
llama-swapを使うことでllama-serverのモデルのロード状態の管理を簡単に行えます。
llama-balancer
今回RTX4070でgpt-oss-20bがかなり早く動くことがわかりました。
また、Ryzen AI Max+ 395はメモリが豊富なため、gpt-oss-20b x 2、gpt-oss-120bの合計3インスタンスを同時に動かせられます。120bインスタンスはllama-swapによって別のモデルに動的に読み替え、20bはRTX4070とRyzen AI Max+ 395 x 2で分散させます。最初の20b利用者にはRTX4070のマシンへ、二人目はRyzen AI Max+ 395へとつなげればいい感じにリクエストをさばけます。
- gpt-oss-20b (RTX4070)
- gpt-oss-20b 128kと切り替え
- gpt-oss-20b (Ryzen AI Max+ 395)常駐
- gpt-oss-20b (Ryzen AI Max+ 395)常駐
- gpt-oss-120b (Ryzen AI Max+ 395)
- もしくは別のモデルに切り替え
オープンソースプロジェクトもあったのですが、シンプルなものが欲しかったためFlaskを使ったシンプルなロードバランサをお試し実装しました。前回のリクエストを処理したインスタンスに流すことでプロンプトキャッシュによって即出力を開始することが出来ます。
エージェントAIでサクッと作ったpythonで、使いまわしが出来るようなものではありませんが、こちらのGitHubに上げました。(なおお手軽さを出すため、あえて1ファイルで作っています。)
機会があればこの辺はまた別記事にしたいと思います。
だいぶ長くなってしまいました。ここまで読んでくださった方ありがとうございます。
それではまた次の機会で。
\ 最新情報をチェック /